12.4: The Central Limit Theorem (Čeština)
The Central Limit Theorem nám říká, že jak se velikosti vzorků zvětšují, rozdělení vzorkování střední hodnoty se stane normálně distribuovaným, dokonce pokud data v každém vzorku nejsou normálně distribuována.
Můžeme to vidět na skutečných datech. Pojďme pracovat s proměnnou AlcoholYear v distribuci NHANES, která je velmi zkosená, jak ukazuje levý panel na obrázku ??. Tato distribuce je pro nedostatek lepšího slova zábavná – a rozhodně není běžně distribuována. Nyní se podívejme na rozdělení vzorkování průměru pro tuto proměnnou. Obrázek 12.2 ukazuje distribuci vzorkování pro tuto proměnnou, která se získá opakovaným čerpáním vzorků velikosti 50 z datového souboru NHANES a průměrem. Navzdory zjevné nenormálnosti původních dat je distribuce vzorkování pozoruhodně blízká normálu.
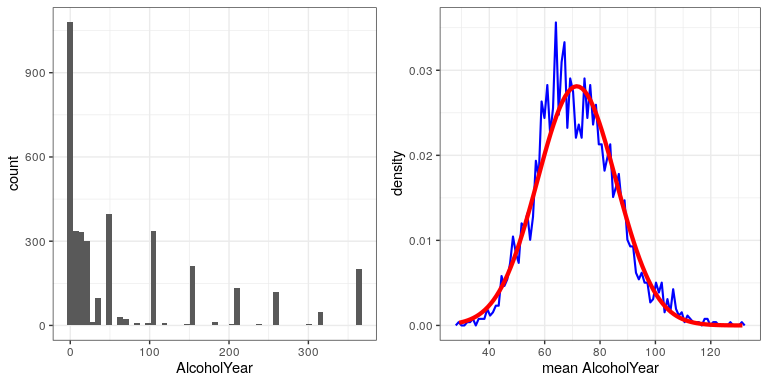
Centrální limitní věta je pro statistiku důležitá, protože nám umožňuje bezpečně předpokládat, že rozdělení vzorkování průměru bude ve většině případů normální. To znamená, že můžeme využít statistických technik, které předpokládají normální rozdělení, jak uvidíme v následující části.