Jak mohu najít duplicitní hodnoty na serveru SQL Server?
V tomto článku se dozvíte, jak najít duplicitní hodnoty v tabulce nebo zobrazení pomocí SQL. Postupem projdeme krok za krokem. Začneme s jednoduchým problémem, pomalu budujeme SQL, dokud nedosáhneme konečného výsledku.
Na konci porozumíte vzoru použitému k identifikaci duplicitních hodnot a budete moci použít v vaše databáze.
Všechny příklady této lekce jsou založeny na Microsoft SQL Server Management Studio a databázi AdventureWorks2012. Tyto bezplatné nástroje můžete začít používat v mé příručce Začínáme s používáním serveru SQL Server.
Najít duplicitní hodnoty na serveru SQL Server
Začněme. Tento článek vycházíme z reálného požadavku; manažer lidských zdrojů by byl rád, kdybyste našli všechny zaměstnance, kteří mají stejné narozeniny. Chtěla by, aby byl seznam seřazen podle Datum narození a Jméno zaměstnance.
Po prohlédnutí databáze je zřejmé, že je použita tabulka HumanResources.Employee, protože obsahuje data narození zaměstnanců.
Na na první pohled se zdá, že by bylo docela snadné najít duplicitní hodnoty na serveru SQL. Nakonec můžeme data snadno seřadit.
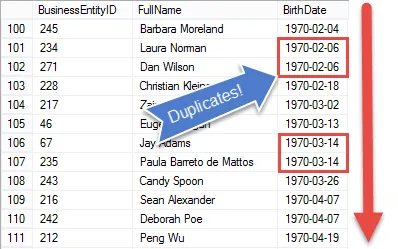
Jakmile jsou však data tříděna, je to těžší! Protože SQL je jazyk založený na množině, není snadný způsob, jak poznat hodnoty předchozího záznamu, kromě použití kurzorů.
Pokud bychom je znali, mohli bychom jen porovnat hodnoty, a když to byly stejný příznak záznamů jako duplikáty.
Naštěstí existuje jiný způsob, jak to udělat. K vyrovnání narozenin zaměstnanců použijeme VNITŘNÍ PŘIPOJENÍ. Tímto způsobem získáme seznam zaměstnanců, kteří sdílejí stejné datum narození.
Bude to článek sestavený za běhu. Začnu jednoduchým dotazem, ukážu výsledky a ukážu, co je třeba vylepšit, a pokračuji. Začneme tím, že získáme seznam zaměstnanců a jejich data narození.
Krok 1 – Získejte seznam zaměstnanců seřazených podle data narození
Při práci s SQL, zejména na nezmapovaném území, Cítím, že je lepší vytvořit prohlášení v malých krocích, ověřovat výsledky, jak jdete, spíše než psát „finální“ SQL v jednom kroku, ale pouze zjistím, že to musím vyřešit.
Tip: Pokud pracujete s velmi velkou databází, pak může mít smysl vytvořit menší kopii jako vaši vývojovou nebo testovací verzi a použít ji k napsání vašich dotazů. Tímto způsobem nezabijete výkon produkční databáze a nepropustíte všechny vy.
Takže v našem prvním kroku uvedeme seznam všech zaměstnanců. Za tímto účelem připojíme tabulku zaměstnanců k tabulce osob, abychom mohli získat jméno zaměstnance.
Tady je zatím dotaz
SELECT E1.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Pokud se podíváte na výsledek, který vidíte, máme všechny prvky požadavku HR manažera, kromě toho zobrazujeme každého zaměstnance
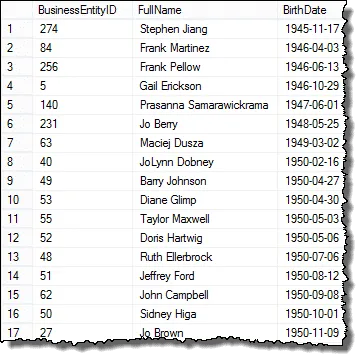
V dalším kroku nastavíme výsledky, abychom mohli začít porovnávat data narození a najít duplicitní hodnoty.
KROK 2 – Porovnání dat narození a identifikace duplikátů.
Nyní, máme seznam zaměstnanců, nyní potřebujeme prostředek k porovnání dat narození, abychom mohli identifikovat zaměstnance se stejnými daty narození. Obecně se jedná o duplicitní hodnoty.
Chcete-li provést srovnání, provedeme vlastní připojení v tabulce zaměstnanců. Vlastní připojení je jen zjednodušená verze VNITŘNÍHO PŘIPOJENÍ. Začínáme používat BirthDate jako naši podmínku připojení. Tím je zajištěno, že načítáme pouze zaměstnance se stejným datem narození.
SELECT E1.BusinessEntityID, E2.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDateORDER BY E1.BirthDate, FullName
Do dotazu jsem přidal E2.BusinessEntityID, abyste mohli porovnat primární klíč z obou E1 a E2. V mnoha případech vidíte, že jsou stejné.
Důvodem, proč se zaměřujeme na BusinessEntityID, je to, že se jedná o primární klíč a jedinečný identifikátor tabulky. Stává se velmi stručným a pohodlným prostředkem k identifikaci výsledků řádku a pochopení jeho zdroje.
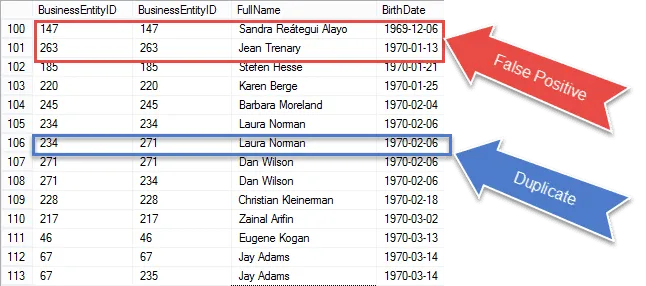
Blížíme se k získání našeho konečného výsledku, ale jakmile se podíváte na výsledky, uvidíte, že jsme ‚ znovu vyzvedáváte stejný záznam v zápase E1 i E2.
Podívejte se na položky označené červeně. To jsou falešná pozitiva, která musíme z našich výsledků vyloučit. Jedná se o stejné řádky, které se k sobě shodují.
Dobrou zprávou je, že jsme opravdu blízko identifikaci duplikátů.
Zakroužkoval jsem 100% zaručený duplikát modře. Všimněte si, že BusinessEntityID se liší. To naznačuje, že se vlastní připojení shoduje s datem narození v různých řádcích – pro jistotu skutečné duplikáty.
V dalším kroku vezmeme tyto falešné pozitivy přímo na hlavu a odstraníme je z našich výsledků.
Krok 3 – Vyloučení shod na stejném řádku – Odstranění falešných pozitiv
V předchozím kroku jste si možná všimli, že všechny falešně pozitivní shody mají stejné BusinessEntityID; vzhledem k tomu, že skutečné duplikáty nebyly stejné.
Toto je naše velká nápověda.
Pokud chceme vidět pouze duplikáty, musíme přinést zpět pouze shody ze spojení, kde Hodnoty BusinessEntityID nejsou stejné.
K tomu můžeme přidat
E2.BusinessEntityID <> E1.BusinessEntityID
Jako podmínku připojení k našemu vlastnímu připojení. Přidanou podmínku jsem vybarvil červeně.
SELECT E1.BusinessEntityID, E2.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Jakmile je tento dotaz spuštěn, uvidíte, že ve výsledcích je méně řádků a těch, které zůstanou jsou skutečně duplikáty.
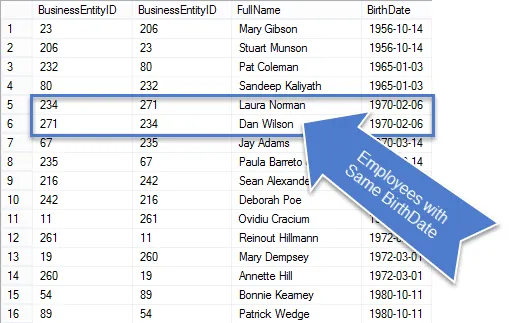
Jelikož se jednalo o obchodní požadavek, vyčistěte dotaz, abychom zobrazovali pouze požadované informace.
Krok 4 – Konečné úpravy
Pojďme zbavit se hodnot BusinessEntityID z dotazu. Byli tam jen proto, aby nám pomohli vyřešit problém.
Konečný dotaz je uveden zde
SELECT P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
A zde jsou výsledky, které můžete prezentovat HR manažer!
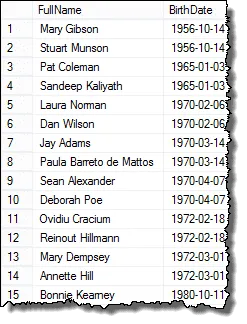
Mark, jeden z mých čtenářů, mě upozornil, že pokud existují tři zaměstnanci se stejnými daty narození, měli byste v konečných výsledcích duplikáty. Ověřil jsem to a to je pravda. Chcete-li vrátit seznam zobrazující každý duplikát pouze jednou, můžete použít klauzuli DISTINCT. Tento dotaz funguje ve všech případech:
SELECT DISTINCT P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Závěrečné komentáře
Zde uvádíme shrnutí kroků, které jsme podnikli k identifikaci duplicitních údajů v naší tabulce .
- Nejprve jsme vytvořili dotaz na data, která chceme zobrazit. V našem příkladu to byl zaměstnanec a jeho datum narození.
- Provedli jsme self-join, INNER JOIN na stejné tabulce v geek speak a pomocí pole jsme považovali za duplikát. V našem případě jsme chtěli najít duplicitní narozeniny.
- Nakonec jsme vyloučili shody se stejným řádkem vyloučením řádků, kde byly primární klíče stejné.
Tím, že krok za krokem můžete vidět, že jsme při tvorbě dotazu potřebovali hodně práce s hádat.
Pokud se snažíte vylepšit způsob psaní svých dotazů, nebo vás všechny jen zmátly a hledali způsob, jak vyčistit mlhu, pak bych mohl navrhnout mého průvodce Tři kroky k lepšímu SQL.