Hvordan kan jeg finde duplikatværdier i SQL Server?
I denne artikel skal du finde ud af, hvordan du finder duplikatværdier i en tabel eller en visning ved hjælp af SQL. Vi går trin for trin gennem processen. Vi starter med et simpelt problem, langsomt opbygger SQL, indtil vi opnår slutresultatet.
Ved udgangen forstår du det mønster, der bruges til at identificere duplikatværdier og er i stand til at bruge i din database.
Alle eksemplerne til denne lektion er baseret på Microsoft SQL Server Management Studio og AdventureWorks2012-databasen. Du kan komme i gang ved hjælp af disse gratis værktøjer ved hjælp af min vejledning Introduktion ved hjælp af SQL Server.
Find duplikatværdier i SQL Server
Lad os komme i gang. Vi baserer denne artikel på en anmodning fra den virkelige verden; personalechefen vil gerne have, at du finder alle medarbejdere, der deler den samme fødselsdag. Hun vil gerne have listen sorteret efter fødselsdato og medarbejdernavn.
Efter at have kigget på databasen bliver det tydeligt, at tabellen HumanResources. Medarbejder skal bruges, da den indeholder fødselsdatoer for medarbejdere.
På ved første øjekast ser det ud som om det ville være ret nemt at finde duplikatværdier i SQL-serveren. Når alt kommer til alt kan vi nemt sortere dataene.
Men når dataene er sorteret, bliver det sværere! Da SQL er et sætbaseret sprog, er der ikke en nem måde, bortset fra at bruge markører, at kende den forrige records værdier.
Hvis vi kendte disse, kunne vi bare sammenligne værdier, og når de var de samme flag poster som duplikater.
Heldigvis er der en anden måde for os at gøre dette på. Vi bruger en INNER JOIN til at matche medarbejdernes fødselsdage. Ved at gøre dette får vi en liste over medarbejdere, der deler den samme fødselsdato.
Dette bliver en build-as you go-artikel. Jeg starter med en simpel forespørgsel, viser resultater og påpeger, hvad der skal forbedres og gå videre. Vi starter med at få en liste over medarbejdere og deres fødselsdatoer.
Trin 1 – Få en liste over medarbejdere sorteret efter fødselsdato
Når du arbejder med SQL, især i ukendt område, Jeg føler, at det er bedre at opbygge en erklæring i små trin og kontrollere resultaterne, mens du går, i stedet for at skrive den “endelige” SQL i et trin for kun at finde, at jeg har brug for at foretage fejlfinding.
Tip: du arbejder med en meget stor database, så kan det give mening at lave en mindre kopi som din dev eller testversion og bruge den til at skrive dine forespørgsler. På den måde dræber du ikke produktionsdatabasens ydeevne og får alle ned på dig.
Så for vores første skridt vil vi liste alle medarbejdere. For at gøre det slutter vi os til medarbejdertabellen til persontabellen, så vi kan få medarbejderens navn.
Her er forespørgslen hidtil
SELECT E1.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
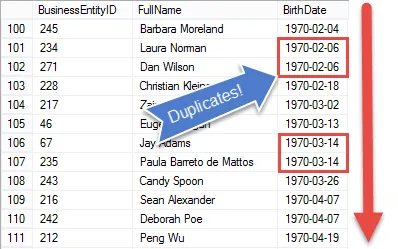
Hvis du ser på resultatet, ser du, at vi har alle elementerne i HR-lederens anmodning, bortset fra at vi viser hver medarbejder
I det næste trin opsætter vi resultaterne, så vi kan begynde at sammenligne fødselsdatoer for at finde duplikatværdier.
TRIN 2 – Sammenlign fødselsdatoer for at identificere duplikater.
Nu hvor vi har en liste over medarbejdere, vi har nu brug for et middel til at sammenligne fødselsdatoer, så vi kan identificere medarbejdere med de samme fødselsdatoer. Generelt er dette duplikatværdier.
For at gøre sammenligningen foretager vi en selvtilslutning på medarbejderbordet. En selvtilslutning er bare en forenklet version af en INNER JOIN. Vi starter med at bruge BirthDate som vores tilslutningsbetingelse. Dette sikrer, at vi kun henter medarbejdere med samme fødselsdato.
SELECT E1.BusinessEntityID, E2.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDateORDER BY E1.BirthDate, FullName
Jeg tilføjede E2.BusinessEntityID til forespørgslen, så du kan sammenligne den primære nøgle fra begge E1 og E2. Du ser i mange tilfælde, at de er de samme.
Årsagen til, at vi fokuserer på BusinessEntityID, er, at det er den primære nøgle og den unikke id for tabellen. Det bliver et meget kortfattet og praktisk middel til at identificere en række resultater og forstå dens kilde.
Vi kommer tættere på at opnå vores endelige resultat, men når du først har tjekket resultaterne, ser vi, genoptager den samme post i både E1 og E2 match.
Tjek de emner, der er cirkuleret med rødt. Det er de falske positive, vi skal fjerne fra vores resultater. Det er de samme rækker, der matcher sig selv.
Den gode nyhed er, at vi virkelig er tæt på bare at identificere duplikaterne.
Jeg cirklede en 100% garanteret duplikat i blåt. Bemærk, at BusinessEntityID’erne er forskellige. Dette indikerer, at selvtilslutning matcher BirthDate på forskellige rækker – ægte duplikater for at være sikre.
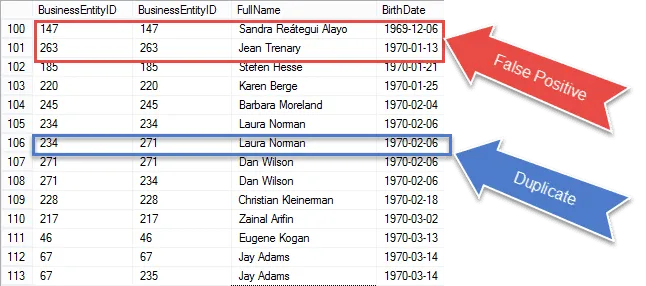
I næste trin tager vi disse falske positive på hovedet og fjerner dem fra vores resultater.
Trin 3 – Fjern matches til samme række – Fjern falske positive
I det forudgående trin har du måske bemærket, at alle de falske positive matches har den samme BusinessEntityID; derimod, at de sande duplikater ikke var ens.
Dette er vores store antydning.
Hvis vi kun vil se duplikater, behøver vi kun bringe kampe tilbage fra sammenføjningen, hvor BusinessEntityID-værdier er ikke ens.
For at gøre dette kan vi tilføje
E2.BusinessEntityID <> E1.BusinessEntityID
Som en sammenføjningsbetingelse til vores selvtilslutning. Jeg har farvet den tilføjede betingelse med rødt.
SELECT E1.BusinessEntityID, E2.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Når denne forespørgsel er kørt, kan du se, at der er færre rækker i resultaterne, og dem, der er tilbage er virkelig dubletter.
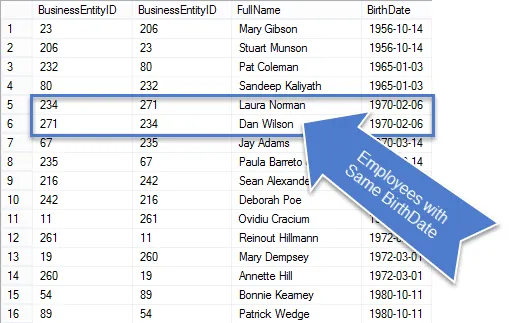
Da dette var en forretningsanmodning, lad os rydde forespørgslen op, så vi kun viser de ønskede oplysninger.
Trin 4 – Sidste hånd
Lad os slippe af med BusinessEntityID-værdierne fra forespørgslen. De var der kun for at hjælpe os med fejlfinding.
Den endelige forespørgsel er angivet her
SELECT P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Og her er de resultater, du kan præsentere for HR Manager!
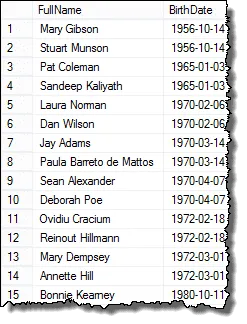
Mark, en af mine læsere, påpegede mig, at hvis der er tre medarbejdere, der har de samme fødselsdatoer, så ville du have duplikater i de endelige resultater. Jeg bekræftede dette, og det er sandt. For at returnere en liste, der kun viser hvert duplikat en gang, kan du bruge DISTINCT-klausulen. Denne forespørgsel fungerer i alle tilfælde:
SELECT DISTINCT P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Endelige kommentarer
For at opsummere her er de trin, vi tog for at identificere duplikatdata i vores tabel .
- Vi oprettede først en forespørgsel om de data, vi vil se. I vores eksempel var dette medarbejderen og deres fødselsdato.
- Vi udførte en selvtilslutning, INNER JOIN på samme bord i nørd tale, og ved hjælp af feltet anså vi det for et duplikat. I vores tilfælde ønskede vi at finde duplikatfødselsdage.
- Endelig eliminerede vi matches til den samme række ved at ekskludere rækker, hvor de primære nøgler var de samme.
Ved at tage en trin for trin tilgang kan du se, at vi tog meget af gættet ud af at oprette forespørgslen.
Hvis du ønsker at forbedre, hvordan du skriver dine forespørgsler eller bare bliver forvirret af det hele og leder efter en måde at rydde tågen på, så kan jeg foreslå min guide Tre trin til bedre SQL.