¿Cómo puedo encontrar valores duplicados en SQL Server?
En este artículo, descubra cómo encontrar valores duplicados en una tabla o vista usando SQL. Avanzaremos paso a paso por el proceso. Comenzaremos con un problema simple, construiremos lentamente el SQL, hasta que logremos el resultado final.
Al final, comprenderá el patrón utilizado para identificar valores duplicados y podrá usarlo en su base de datos.
Todos los ejemplos de esta lección están basados en Microsoft SQL Server Management Studio y la base de datos AdventureWorks2012. Puede empezar a utilizar estas herramientas gratuitas con mi Guía de introducción a SQL Server.
Buscar valores duplicados en SQL Server
Empecemos. Basaremos este artículo en una solicitud del mundo real; el gerente de recursos humanos desea que encuentre a todos los empleados que comparten el mismo cumpleaños. A ella le gustaría que la lista estuviera ordenada por Fecha de nacimiento y Nombre del empleado.
Después de mirar la base de datos, se hace evidente que la tabla Recursos humanos.Empleado es la que debe usar, ya que contiene las fechas de nacimiento de los empleados.
En A primera vista, parece que sería bastante fácil encontrar valores duplicados en el servidor SQL. Después de todo, podemos ordenar los datos fácilmente.
¡Pero una vez ordenados los datos, se vuelve más difícil! Dado que SQL es un lenguaje basado en conjuntos, no hay una manera fácil, excepto mediante el uso de cursores, de conocer los valores del registro anterior.
Si los supiéramos, podríamos comparar valores y cuándo fueron los mismo marca los registros como duplicados.
Afortunadamente, hay otra forma de hacer esto. Usaremos INNER JOIN para coincidir con los cumpleaños de los empleados. Al hacerlo, obtendremos una lista de empleados que comparten la misma fecha de nacimiento.
Este será un artículo que se irá construyendo sobre la marcha. Comenzaré con una consulta simple, mostraré los resultados, señalaré lo que necesita mejorar y seguiré adelante. Comenzaremos obteniendo una lista de empleados y sus fechas de nacimiento.
Paso 1: Obtenga una lista de empleados ordenados por fecha de nacimiento
Cuando trabaje con SQL, especialmente en territorios inexplorados, Creo que es mejor crear una declaración en pequeños pasos, verificando los resultados a medida que avanza, en lugar de escribir el SQL «final» en un solo paso, para encontrar solo que necesito solucionarlo.
Sugerencia: si está trabajando con una base de datos muy grande, entonces puede tener sentido hacer una copia más pequeña como su versión de desarrollo o prueba y usarla para escribir sus consultas. De esa manera, no mata el rendimiento de la base de datos de producción y hace que todos se sientan mal usted.
Entonces, para nuestro primer paso, vamos a enumerar todos los empleados. Para hacerlo, uniremos la tabla de Empleados a la tabla de Personas para que podamos obtener el nombre del empleado.
Aquí está la consulta hasta ahora
SELECT E1.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
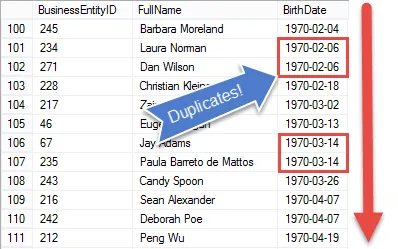
Si observa el resultado, verá que tenemos todos los elementos de la solicitud del gerente de recursos humanos, excepto que estamos mostrando a todos los empleados
En el siguiente paso, configuraremos los resultados para que podamos comenzar a comparar fechas de nacimiento para encontrar valores duplicados.
PASO 2: Comparar fechas de nacimiento para identificar duplicados.
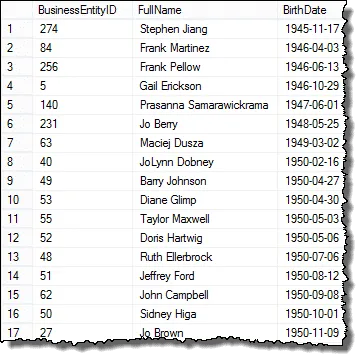
Ahora que tenemos una lista de empleados, ahora necesitamos un medio para comparar las fechas de nacimiento para poder identificar a los empleados con las mismas fechas de nacimiento. En general, estos son valores duplicados.
Para hacer la comparación, realizaremos una autocompensación en la tabla de empleados. Una autocombinación es solo una versión simplificada de una INNER JOIN. Comenzamos usando BirthDate como nuestra condición de unión. Esto garantiza que solo recuperemos empleados con la misma fecha de nacimiento.
SELECT E1.BusinessEntityID, E2.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDateORDER BY E1.BirthDate, FullName
Agregué E2.BusinessEntityID a la consulta para que pueda comparar la clave principal de ambos E1 y E2. En muchos casos, verá que son iguales.
La razón por la que nos centramos en BusinessEntityID es que es la clave principal y el identificador único de la tabla. Se convierte en un medio muy conciso y conveniente para identificar los resultados de una fila y comprender su origen.
Estamos cada vez más cerca de obtener nuestro resultado final, pero una vez que revise los resultados, verá que ‘ Estás obteniendo el mismo récord tanto en el partido E1 como en el E2.
Mira los elementos encerrados en un círculo rojo. Esos son los falsos positivos que debemos eliminar de nuestros resultados. Esas son las mismas filas que coinciden con ellas mismas.
La buena noticia es que estamos muy cerca de identificar los duplicados.
Marqué con un círculo un duplicado 100% garantizado en azul. Tenga en cuenta que los BusinessEntityID son diferentes. Esto indica que la autounión coincide con la fecha de nacimiento en diferentes filas; duplicados verdaderos para estar seguro.
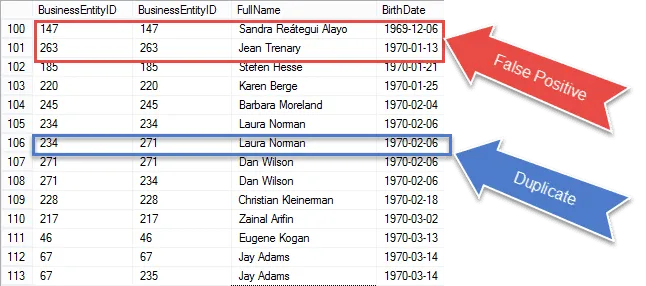
En el siguiente paso, tomaremos esos falsos positivos y los eliminaremos de nuestros resultados.
Paso 3: eliminar coincidencias en la misma fila: eliminar falsos positivos
En el paso anterior, es posible que haya notado que todas las coincidencias falsas positivas tienen el mismo BusinessEntityID; mientras que los verdaderos duplicados no eran iguales.
Esta es nuestra gran pista.
Si solo queremos ver duplicados, entonces solo necesitamos traer coincidencias de la combinación donde el Los valores de BusinessEntityID no son iguales.
Para hacer esto podemos agregar
E2.BusinessEntityID <> E1.BusinessEntityID
Como condición de unión a nuestra autounión. He coloreado la condición agregada en rojo.
SELECT E1.BusinessEntityID, E2.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Una vez que se ejecute esta consulta, verá que hay menos filas en los resultados y las que quedan son realmente duplicados.
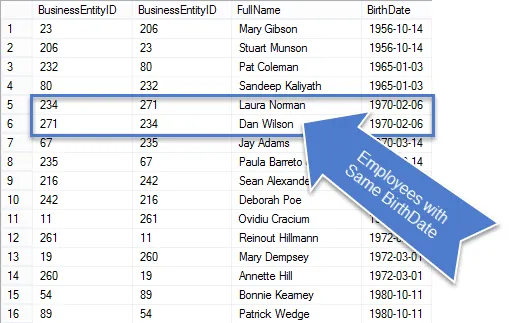
Dado que se trataba de una solicitud comercial, limpiemos la consulta para que solo mostremos la información solicitada.
Paso 4: Toques finales
Vamos deshacerse de los valores BusinessEntityID de la consulta. Estaban allí solo para ayudarnos a solucionar problemas.
La consulta final se enumera aquí
SELECT P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Y estos son los resultados que puede presentar a el gerente de recursos humanos!
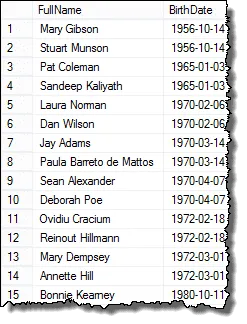
Mark, uno de mis lectores, me señaló que si hay tres empleados que tienen las mismas fechas de nacimiento, entonces tendría duplicados en los resultados finales. Verifiqué esto y eso es cierto. Para devolver una lista y mostrar cada duplicado solo una vez, puede usar la cláusula DISTINCT. Esta consulta funciona en todos los casos:
SELECT DISTINCT P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Comentarios finales
Para resumir, aquí están los pasos que tomamos para identificar datos duplicados en nuestra tabla. .
- Primero creamos una consulta de los datos que queremos ver. En nuestro ejemplo, este era el empleado y su fecha de nacimiento.
- Realizamos una autounión, INNER JOIN en la misma mesa en lenguaje geek, y usando el campo consideramos un duplicado. En nuestro caso, queríamos encontrar cumpleaños duplicados.
- Finalmente, eliminamos las coincidencias con la misma fila al excluir las filas donde las claves primarias eran las mismas.
Al tomar un enfoque paso a paso, puede ver que eliminamos muchas de las conjeturas al crear la consulta.
Si está buscando mejorar la forma en que escribe sus consultas o simplemente está confundido por todo y busca una forma de despejar la niebla, entonces puedo sugerir mi guía Tres pasos para mejorar el SQL.