Comment puis-je trouver des valeurs en double dans SQL Server?
Dans cet article, découvrez comment trouver des valeurs en double dans une table ou une vue à l’aide de SQL. Nous allons suivre étape par étape le processus. Nous allons commencer par un problème simple, construire lentement le SQL, jusqu’à ce que nous obtenions le résultat final.
À la fin, vous comprendrez le modèle utilisé pour identifier les valeurs en double et pourrez l’utiliser dans votre base de données.
Tous les exemples de cette leçon sont basés sur Microsoft SQL Server Management Studio et la base de données AdventureWorks2012. Vous pouvez commencer à utiliser ces outils gratuits en utilisant mon Guide Premiers pas avec SQL Server.
Recherche de valeurs en double dans SQL Server
Commençons. Nous baserons cet article sur une demande réelle; le responsable des ressources humaines souhaite que vous trouviez tous les employés partageant le même anniversaire. Elle aimerait que la liste soit triée par Date de naissance et Nom d’employé.
Après avoir consulté la base de données, il devient évident que la table HumanResources.Employee est celle à utiliser car elle contient les dates de naissance des employés.
À à première vue, il semble qu’il serait assez facile de trouver des valeurs en double dans le serveur SQL. Après tout, nous pouvons facilement trier les données.
Mais une fois les données triées, cela devient plus difficile! Étant donné que SQL est un langage basé sur des ensembles, il n’y a pas de moyen facile, à l’exception de l’utilisation de curseurs, de connaître les valeurs de l’enregistrement précédent.
Si nous les connaissions, nous pourrions simplement comparer les valeurs, et quand elles étaient même signaler les enregistrements comme doublons.
Heureusement, il existe une autre façon pour nous de faire cela. Nous utiliserons un INNER JOIN pour faire correspondre les anniversaires des employés. Ce faisant, nous obtiendrons une liste des employés partageant la même date de naissance.
Ce sera un article de construction au fur et à mesure. Je vais commencer par une simple requête, afficher les résultats et indiquer ce qui doit être affiné et passer à autre chose. Nous allons commencer par obtenir une liste des employés et leurs dates de naissance.
Étape 1 – Obtenir une liste des employés triée par date de naissance
Lorsque vous travaillez avec SQL, en particulier en territoire inconnu, Je pense qu’il est préférable de créer une déclaration par petites étapes, en vérifiant les résultats au fur et à mesure, plutôt que d’écrire le SQL « final » en une seule étape, pour ne constater que j’ai besoin de le dépanner.
Conseil: Si vous travaillez avec une base de données très volumineuse, il peut être judicieux d’en faire une copie plus petite en tant que version de développement ou de test et de l’utiliser pour écrire vos requêtes. De cette façon, vous ne tuez pas les performances de la base de données de production et n’abusez pas tout le monde
Pour notre première étape, nous allons donc lister tous les employés. Pour ce faire, nous joignons la table Employé à la table Personne afin que nous puissions obtenir le nom de l’employé.
Voici la requête jusqu’à présent
SELECT E1.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
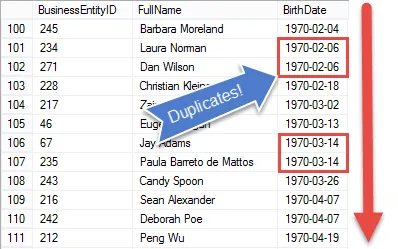
Si vous regardez le résultat, vous voyez que nous avons tous les éléments de la demande du responsable RH, sauf que nous affichons chaque employé
Dans l’étape suivante, nous configurerons les résultats afin que nous puissions commencer à comparer les dates de naissance pour trouver des valeurs en double.
ÉTAPE 2 – Comparer les dates de naissance pour identifier les doublons.
Maintenant que nous avons une liste d’employés, nous avons maintenant besoin d’un moyen de comparer les dates de naissance afin que nous puissions identifier les employés ayant les mêmes dates de naissance. En général, ce sont des valeurs en double.
Pour faire la comparaison, nous allons faire une auto-jointure sur la table des employés. Une auto-jointure est juste une version simplifiée d’un INNER JOIN. Nous commençons à utiliser BirthDate comme condition de jointure. Cela garantit que nous ne récupérons que les employés ayant la même date de naissance.
SELECT E1.BusinessEntityID, E2.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDateORDER BY E1.BirthDate, FullName
J’ai ajouté E2.BusinessEntityID à la requête afin que vous puissiez comparer la clé primaire des deux E1 et E2. Vous voyez dans de nombreux cas qu’ils sont identiques.
La raison pour laquelle nous nous concentrons sur BusinessEntityID est qu’il s’agit de la clé primaire et de l’identifiant unique de la table. Cela devient un moyen très concis et pratique d’identifier les résultats d’une ligne et de comprendre sa source.
Nous nous rapprochons de l’obtention de notre résultat final, mais une fois que vous aurez vérifié les résultats, vous verrez que nous ‘ re ramasser le même record dans le match E1 et E2.
Regardez les éléments entourés en rouge. Ce sont les faux positifs que nous devons éliminer de nos résultats. Ce sont les mêmes lignes qui correspondent à elles-mêmes.
La bonne nouvelle est que nous sommes sur le point d’identifier simplement les doublons.
J’ai entouré un doublon garanti à 100% en bleu. Notez que les BusinessEntityID sont différents. Cela indique que l’auto-jointure correspond à BirthDate sur différentes lignes – de vrais doublons pour être sûr.
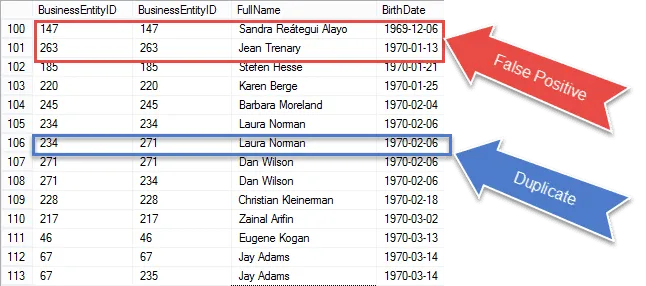
Dans l’étape suivante, nous examinerons ces faux positifs de front et les supprimerons de nos résultats.
Étape 3 – Éliminer les correspondances à la même ligne – Supprimer les faux positifs
Dans l’étape précédente, vous avez peut-être remarqué que toutes les fausses correspondances positives ont le même BusinessEntityID; alors que les vrais doublons n’étaient pas égaux.
Ceci est notre gros indice.
Si nous voulons voir uniquement les doublons, alors nous devons uniquement ramener les correspondances de la jointure où le Les valeurs BusinessEntityID ne sont pas égales.
Pour ce faire, nous pouvons ajouter
E2.BusinessEntityID <> E1.BusinessEntityID
comme condition de jointure à notre auto-jointure. J’ai coloré la condition ajoutée en rouge.
SELECT E1.BusinessEntityID, E2.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Une fois cette requête exécutée, vous verrez qu’il y a moins de lignes dans les résultats, et celles qui restent sont vraiment des doublons.
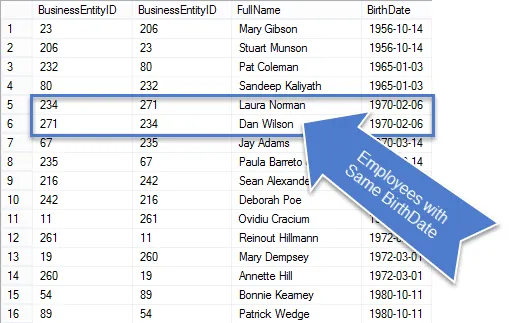
Puisqu’il s’agissait d’une demande commerciale, nettoyons la requête afin de ne montrer que les informations demandées.
Étape 4 – Touches finales
Allons supprimez les valeurs BusinessEntityID de la requête. Ils n’étaient là que pour nous aider à résoudre les problèmes.
La requête finale est répertoriée ici
SELECT P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Et voici les résultats que vous pouvez présenter le responsable des ressources humaines!
Mark, l’un de mes lecteurs, m’a fait remarquer que s’il y a trois employés qui ont les mêmes dates de naissance, alors vous auriez des doublons dans les résultats finaux. J’ai vérifié ceci et c’est vrai. Pour renvoyer une liste affichant chaque doublon une seule fois, vous pouvez utiliser la clause DISTINCT. Cette requête fonctionne dans tous les cas:
SELECT DISTINCT P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Commentaires finaux
Pour résumer, voici les étapes que nous avons prises pour identifier les données en double dans notre tableau .
- Nous avons d’abord créé une requête des données que nous voulons afficher. Dans notre exemple, il s’agissait de l’employé et de sa date de naissance.
- Nous avons effectué une auto-jointure, INNER JOIN sur la même table en geek speak, et en utilisant le champ que nous avons considéré comme dupliqué. Dans notre cas, nous voulions trouver des anniversaires en double.
- Enfin, nous avons éliminé les correspondances à la même ligne en excluant les lignes où les clés primaires étaient les mêmes.
En prenant un approche étape par étape, vous pouvez voir que nous avons simplifié la création de la requête.
Si vous cherchez à améliorer la façon dont vous rédigez vos requêtes ou si vous êtes simplement déconcerté par tout cela et recherchez un moyen d’éliminer le brouillard, puis-je suggérer mon guide Three Steps to Better SQL.