Hogyan találhatok meg duplikált értékeket az SQL Serverben?
Ebben a cikkben megtudhatja, hogyan lehet duplikált értékeket találni egy táblázatban vagy nézetben az SQL használatával. Lépésről lépésre végigmegyünk a folyamaton. Kezdünk egy egyszerű problémával, lassan építjük fel az SQL-t, amíg el nem érjük a végeredményt.
A végére megérti az ismétlődő értékek azonosításához használt mintát, és képes lesz használni az az adatbázisod.
A lecke összes példája a Microsoft SQL Server Management Studio és az AdventureWorks2012 adatbázisra épül. Ezeknek az ingyenes eszközöknek a használatát az Első lépések az SQL Server használatával című útmutatóm használatával kezdheti el.
Ismétlődő értékek keresése az SQL Server szolgáltatásban
Kezdjük. Ezt a cikket egy valós igényre alapozzuk; az emberi erőforrás menedzser szeretné, ha megtalálná az összes alkalmazottat ugyanazon a születésnapon. Szeretné, ha a lista BirthDate és EmployeeName szerint lenne rendezve.
Az adatbázis megtekintése után nyilvánvalóvá válik a HumanResources. A munkavállalói táblát kell használni, mivel tartalmazza az alkalmazottak születési dátumát.
At első pillantásra úgy tűnik, hogy elég egyszerű lenne duplikált értékeket találni az SQL szerveren. Végül is könnyen rendezhetjük az adatokat.
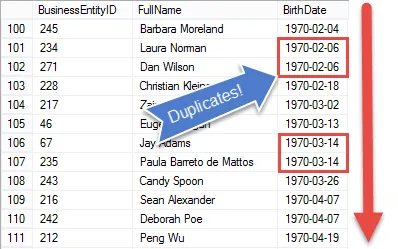
De az adatok rendezése után nehezebbé válik! Mivel az SQL halmazalapú nyelv, a kurzorok kivételével nincs egyszerű módja az előző rekord értékeinek megismerésére.
Ha ezeket ismernénk, akkor csak összehasonlíthatnánk az értékeket, és amikor azok voltak ugyanazokat a bejegyzéseket másolatokként jelölje meg.
Szerencsére van egy másik módunk is erre. BELSŐ CSATLAKOZÁST fogunk használni az alkalmazottak születésnapjainak megegyezéséhez. Ezzel megszerezzük azon alkalmazottak listáját, akik ugyanazt a születési dátumot használják.
Ez egy építkezés közbeni cikk lesz. Kezdem egy egyszerű lekérdezéssel, megmutatom az eredményeket, és rámutatok arra, hogy mit kell finomítani, és továbblépek. Kezdjük az alkalmazottak és születési dátumaik listájának összeállításával.
1. lépés – Szerezzen be egy alkalmazotti listát születési dátum szerint rendezve
Ha SQL-szel dolgozik, különösen még be nem térképezett területen, Úgy érzem, hogy jobb, ha kis lépésekben állítunk elő egy állítást, és közben ellenőrizzük az eredményeket, ahelyett, hogy egy lépésben írnám a “végső” SQL-t, hogy csak nekem kell elhárítanom.
Tipp: Ha nagyon nagy adatbázissal dolgozik, akkor érdemes lehet kisebb példányt készítenie fejlesztőként vagy tesztverzióként, és ezt felhasználhatja a kérdéseinek megírásához. Így nem fogja megölni a termelési adatbázis teljesítményét, és mindenkit lerázni te.
Tehát első lépésként az összes alkalmazottat felsoroljuk. Ehhez csatlakozunk az Alkalmazottak táblához a Személy táblához, hogy megkaphassuk az alkalmazott nevét.
Itt van az eddigi lekérdezés
SELECT E1.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Ha megnézi az eredményt, akkor látja, hogy a HR vezető kérésének minden eleme megvan, kivéve minden alkalmazottat megjelenítünk
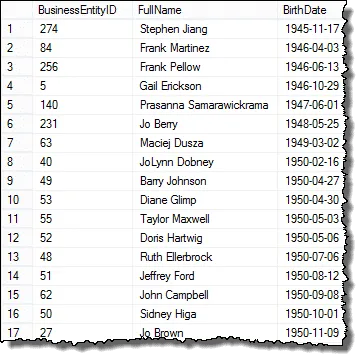
A következő lépésben beállítjuk az eredményeket, hogy elkezdhessük összehasonlítani a születési dátumokat, hogy megkeresjük az ismétlődő értékeket.
2. LÉPÉS – Hasonlítsa össze a születési dátumokat a duplikátumok azonosításához.
Most, hogy van egy alkalmazotti listánk, most szükségünk van egy eszközre a születési dátumok összehasonlításához, hogy azonosíthassuk az azonos születési dátumokkal rendelkező munkavállalókat. Általában ezek ismétlődő értékek.
Az összehasonlítás elvégzéséhez önállóan csatlakozunk az alkalmazottak asztalához. Az öncsatlakozás csak a BELSŐ CSATLAKOZÁS egyszerűsített változata. Először a BirthDate-et használjuk csatlakozási feltételként. Ez biztosítja, hogy csak azonos születési dátummal rendelkező munkavállalókat kapjunk be.
SELECT E1.BusinessEntityID, E2.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDateORDER BY E1.BirthDate, FullName
Hozzáadtam az E2.BusinessEntityID azonosítót a lekérdezéshez, hogy összehasonlíthassa mindkettő elsődleges kulcsát. E1 és E2. Sok esetben azt látja, hogy azonosak.
A BusinessEntityID-re összpontosítunk, mert ez az elsődleges kulcs és a tábla egyedi azonosítója. Nagyon tömör és kényelmes eszközzé válik a sor eredményeinek azonosítására és a forrás megértésére.
Közelebb állunk a végeredmény megszerzéséhez, de miután megnézte az eredményeket, látni fogja, hogy ” újra megszerzi ugyanazt a rekordot mind az E1, mind az E2 mérkőzésen.
Nézze meg a pirossal karikázott elemeket. Ezeket a hamis pozitívumokat ki kell küszöbölnünk eredményeinkből. Ezek ugyanazok a sorok felelnek meg maguknak.
A jó hír az, hogy valóban közel állunk a másolatok azonosításához.
Kék színben karikáztam be a 100% -ban garantált másolatot. Figyelje meg, hogy a BusinessEntityID azonosak. Ez azt jelzi, hogy az öncsatlakozás megfelel a BirthDate-nek a különböző sorokban – az igaz duplikátumok.
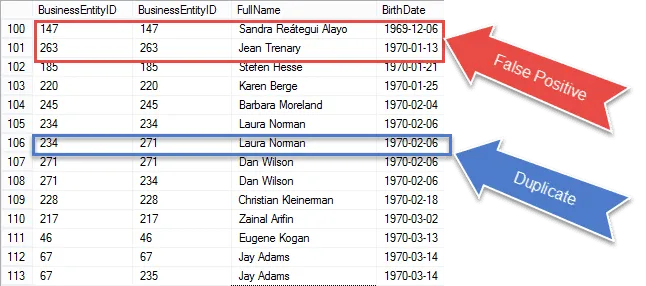
A következő lépésben ezeket a hamis pozitívumokat vesszük figyelembe, és eltávolítjuk az eredményeinkből.
3. lépés – Az egyező sorok egyezésének kiküszöbölése – a hamis pozitív adatok eltávolítása
Az előző lépésben észrevehette, hogy az összes hamis pozitív egyezésnek ugyanaz a BusinessEntityID azonosítója; mivel az igazi duplikátumok nem voltak egyenlőek.
Ez a mi nagy célunk.
Ha csak duplikátumokat akarunk látni, akkor csak a csatlakozásból kell visszahoznunk a mérkőzéseket, ahol a A BusinessEntityID értékek nem egyenlőek.
Ehhez hozzáadhatunk
E2.BusinessEntityID <> E1.BusinessEntityID
Csatlakozási feltételként az öncsatlakozáshoz. Pirosan színeztem a hozzáadott feltételt.
SELECT E1.BusinessEntityID, E2.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
A lekérdezés futtatása után kevesebb eredmény jelenik meg a találatok között, valóban duplikátumok.
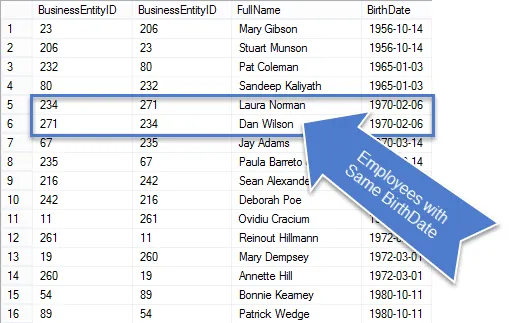
Mivel ez üzleti kérés volt, tisztítsuk meg a lekérdezést, hogy csak a kért információkat jelenítsük meg.
4. lépés – Utolsó simítások
Nézzük megszabaduljon a BusinessEntityID értékeitől a lekérdezésből. Csak azért voltak, hogy segítsenek nekünk a hibaelhárításban.
A végső lekérdezés itt található.
SELECT P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
És itt láthatja az eredményeket a HR menedzser!
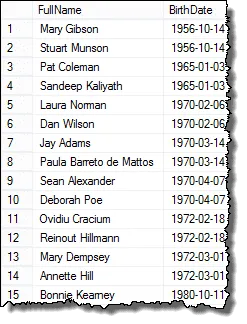
Mark, az egyik olvasóm, rámutatott, hogy ha van három alkalmazott, akiknek azonos a születési dátuma, akkor a végeredményben duplikátumok lennének. Ezt igazoltam, és ez igaz. Ha vissza akar adni egy listát, amely minden duplikátumot csak egyszer mutat be, használhatja a DISTINCT záradékot. Ez a lekérdezés minden esetben működik:
SELECT DISTINCT P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Végső megjegyzések
Összefoglalva az alábbiakban ismertetjük azokat a lépéseket, amelyeket a táblázatban lévő ismétlődő adatok azonosításához tettünk. .
- Először létrehoztunk egy lekérdezést a megtekinteni kívánt adatokról. Példánkban ez volt az alkalmazott és a születési dátumuk.
- Önálló csatlakozást hajtottunk végre, INNER JOIN egyazon asztalon, geek beszédben, és a mezőt megismételtnek tekintettük. Esetünkben duplikált születésnapokat akartunk találni.
- Végül kiküszöböltük az azonos sorba tartozó egyezéseket, kizárva azokat a sorokat, ahol az elsődleges kulcsok megegyeztek.
A lépésről lépésre láthatja, hogy rengeteg találgatást vettünk igénybe a lekérdezés létrehozásakor.
Ha javítani szeretne a lekérdezések megírásán, vagy csak összezavarja az egész, és a köd megtisztításának módja, akkor javasolhatom az Útmutatót a három lépés a jobb SQL-hez