Algoritmo K-Nearest Neighbor (KNN) per l’apprendimento automatico
- K-Nearest Neighbor è uno dei più semplici algoritmi di machine learning basato sulla tecnica di apprendimento supervisionato.
- L’algoritmo K-NN assume la somiglianza tra il nuovo caso / dati e i casi disponibili e colloca il nuovo caso nella categoria più simile alle categorie disponibili.
- L’algoritmo K-NN può essere utilizzato sia per la regressione che per la classificazione, ma principalmente viene utilizzato per i problemi di classificazione.
- K-NN è un algoritmo non parametrico, il che significa non fa alcuna supposizione sui dati sottostanti.
- È anche chiamato algoritmo per apprendere pigri perché non apprende immediatamente dal set di addestramento, ma memorizza il set di dati e al momento della classificazione esegue un azione sul set di dati.
- L’algoritmo KNN nella fase di addestramento memorizza semplicemente il set di dati e quando riceve nuovi dati, classifica quei dati in una categoria molto simile ai nuovi dati.
- Esempio: supponiamo di avere un’immagine di una creatura che assomiglia a un gatto e un cane, ma vogliamo sapere se è un gatto o un cane. Quindi per questa identificazione, possiamo usare l’algoritmo KNN, poiché funziona su una misura di somiglianza. Il nostro modello KNN troverà le caratteristiche simili del nuovo set di dati alle immagini di cani e gatti e in base alle caratteristiche più simili lo inserirà nella categoria cane o gatto.

Perché abbiamo bisogno di un algoritmo K-NN?
Supponiamo che ci siano due categorie, ad esempio, Categoria A e Categoria B, e abbiamo un nuovo punto dati x1, quindi questo punto di dati si troverà in quale di queste categorie. Per risolvere questo tipo di problema, abbiamo bisogno di un algoritmo K-NN. Con l’aiuto di K-NN, possiamo facilmente identificare la categoria o la classe di un particolare set di dati. Considera il diagramma seguente:

Come funziona K-NN?
Il funzionamento di K-NN può essere spiegato sulla base di l’algoritmo seguente:
- Passaggio 1: selezionare il numero K dei vicini
- Passaggio 2: calcolare la distanza euclidea di K numero di vicini
- Passaggio 3: prendere i K vicini più vicini in base alla distanza euclidea calcolata.
- Passaggio 4: tra questi k vicini, contare il numero di punti dati in ciascuna categoria.
- Passaggio 5: Assegna i nuovi punti dati a quella categoria per la quale il numero del vicino è massimo.
- Passaggio 6: Il nostro modello è pronto.
Supponiamo di avere un nuovo punto dati e di doverlo inserire nella categoria richiesta. Considera l’immagine seguente:

- In primo luogo, sceglieremo il numero di vicini, quindi sceglieremo k = 5.
- Successivamente, calcoleremo la distanza euclidea tra i punti dati. La distanza euclidea è la distanza tra due punti, che abbiamo già studiato in geometria. Può essere calcolato come:

- Calcolando la distanza euclidea abbiamo ottenuto i vicini più vicini, come tre vicini più vicini nella categoria A e due vicini più vicini nella categoria B. Considera l’immagine seguente:

- Come possiamo vedere i 3 vicini più vicini provengono dalla categoria A, quindi questo nuovo punto dati deve appartenere alla categoria A.
Come selezionare il valore di K nell’algoritmo K-NN?
Di seguito sono riportati alcuni punti per ricorda mentre selezioni il valore di K nell’algoritmo K-NN:
- Non esiste un modo particolare per determinare il valore migliore per “K”, quindi dobbiamo provare alcuni valori per trovare il migliore fuori di loro. Il valore preferito per K è 5.
- Un valore molto basso per K come K = 1 o K = 2, può essere rumoroso e portare agli effetti di valori anomali nel modello.
- Valori grandi per K sono buoni, ma potrebbero incontrare alcune difficoltà.
Vantaggi dell’algoritmo KNN:
- È semplice da implementare.
- È affidabile rispetto ai dati di addestramento rumorosi
- Può essere più efficace se i dati di addestramento sono grandi.
Svantaggi dell’algoritmo KNN:
- Deve sempre determinare il valore di K che può essere complesso un po ‘di tempo.
- Il costo di calcolo è elevato a causa del calcolo della distanza tra i punti di dati per tutti i campioni di addestramento .
Implementazione Python dell’algoritmo KNN
Per eseguire l’implementazione Python dell’algoritmo K-NN, useremo lo stesso problema e set di dati che abbiamo usato in Regressione logistica. Ma qui miglioreremo le prestazioni del modello. Di seguito è riportata la descrizione del problema:
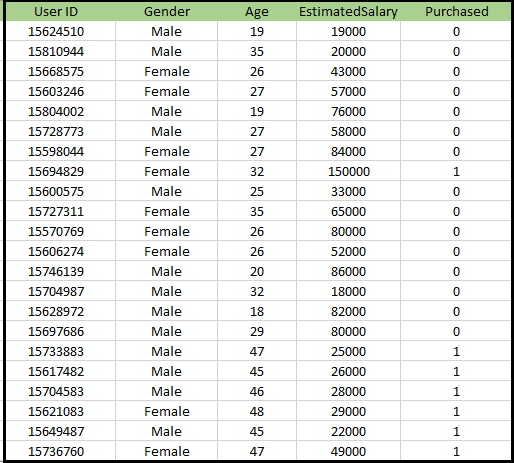
Problema per l’algoritmo K-NN: esiste una casa automobilistica che ha prodotto un nuovo SUV.L’azienda vuole fornire gli annunci agli utenti interessati all’acquisto di quel SUV. Quindi, per questo problema, abbiamo un set di dati che contiene informazioni su più utenti attraverso il social network. Il set di dati contiene molte informazioni ma lo stipendio stimato e l’età verranno presi in considerazione per la variabile indipendente e la variabile Acquistato è per la variabile dipendente. Di seguito è riportato il set di dati:
Passaggi per implementare l’algoritmo K-NN:
- Passaggio di pre-elaborazione dei dati
- Adattamento dell’algoritmo K-NN al set di addestramento
- Previsione del risultato del test
- Accuratezza del test del risultato (matrice di creazione della confusione)
- Visualizzazione del risultato del set di test.
Fase di pre-elaborazione dei dati:
La fase di pre-elaborazione dei dati rimarrà esattamente la stessa della regressione logistica. Di seguito è riportato il codice per questo:
Eseguendo il codice sopra, il nostro set di dati viene importato nel nostro programma e ben pre-elaborato. Dopo il ridimensionamento della funzione, il nostro set di dati di prova sarà simile a:
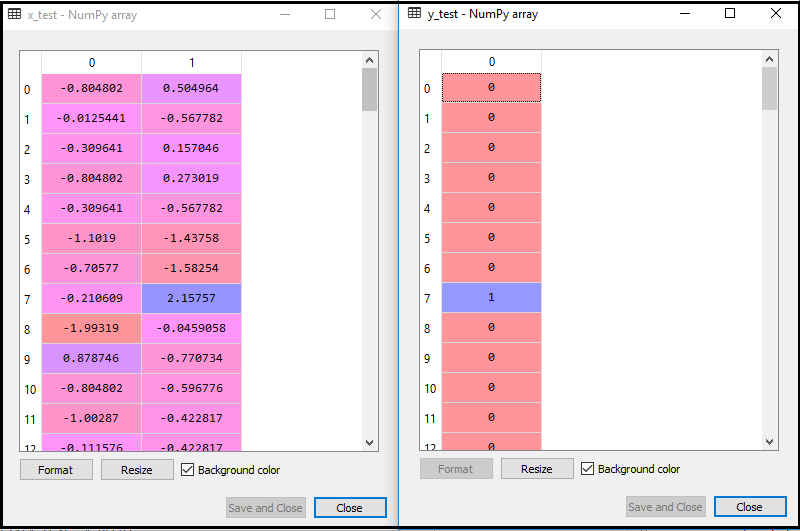
Dall’output sopra im età, possiamo vedere che i nostri dati sono stati ridimensionati con successo.
- Adattamento del classificatore K-NN ai dati di addestramento:
ora adatteremo il classificatore K-NN ai dati di addestramento. Per fare ciò importeremo la classe KNeighborsClassifier della libreria Sklearn Neighbors. Dopo aver importato la classe, creeremo l’oggetto Classifier della classe. Il parametro di questa classe sarà- n_neighbors: per definire i vicini richiesti dell’algoritmo. Di solito, ne occorrono 5.
- metric = “minkowski”: questo è il parametro predefinito e decide la distanza tra i punti.
- p = 2: è equivalente allo standard Metrica euclidea.
Quindi adatteremo il classificatore ai dati di addestramento. Di seguito è riportato il codice:
Output: eseguendo il codice sopra, otterremo l’output come:
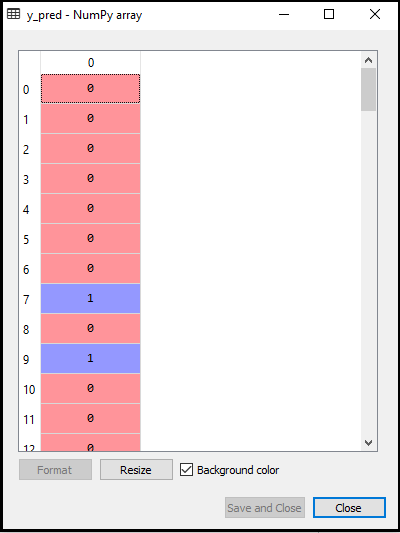
- Previsione del risultato del test: per prevedere il risultato del set di test, creeremo un vettore y_pred come abbiamo fatto in Regressione logistica. Di seguito è riportato il codice per esso:
Output:
L’output per il codice precedente sarà:
- Creazione della matrice di confusione:
ora creeremo la matrice di confusione per il nostro modello K-NN per vedere l’accuratezza del classificatore. Di seguito è riportato il codice:
Nel codice precedente, abbiamo importato la funzione confusion_matrix e l’abbiamo chiamata utilizzando la variabile cm.
Risultato: eseguendo il codice sopra, otterremo la matrice come di seguito:
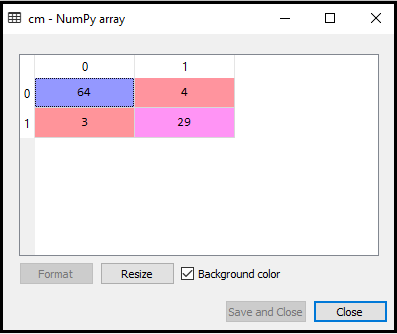
Nell’immagine sopra, possiamo vedere ci sono 64 + 29 = 93 previsioni corrette e 3 + 4 = 7 previsioni errate, mentre, nella regressione logistica, c’erano 11 previsioni errate. Quindi possiamo dire che le prestazioni del modello sono migliorate utilizzando l’algoritmo K-NN.
- Visualizzazione del risultato dell’insieme di addestramento:
ora visualizzeremo il risultato dell’insieme di addestramento per K -Modello NN. Il codice rimarrà lo stesso che abbiamo fatto in Regressione logistica, tranne il nome del grafico. Di seguito è riportato il codice per esso:
Output:
Eseguendo il codice sopra, otterremo il grafico seguente:
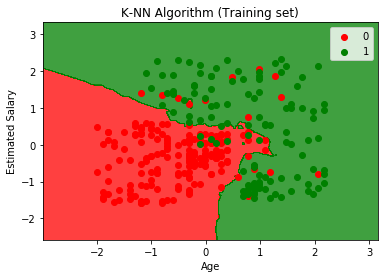
Il grafico di output è diverso dal grafico che si è verificato in Regressione logistica. Può essere compreso nei punti seguenti:
- Come possiamo vedere il grafico mostra il punto rosso e i punti verdi. I punti verdi sono per la variabile Acquistato (1) e Punti rossi per la variabile non Acquistato (0).
- Il grafico mostra un confine irregolare invece di mostrare una linea retta o una curva perché è un algoritmo K-NN, cioè trova il vicino più vicino.
- Il grafico ha classificato gli utenti nelle categorie corrette poiché la maggior parte degli utenti che non hanno acquistato il SUV si trova nella regione rossa e gli utenti che hanno acquistato il SUV si trovano nella regione verde.
- Il grafico mostra un buon risultato, ma ci sono ancora alcuni punti verdi nella regione rossa e punti rossi nella regione verde. Ma questo non è un grosso problema perché così facendo si evitano problemi di overfitting con questo modello.
- Quindi il nostro modello è ben addestrato.
- Visualizzazione del risultato del set di test:
Dopo l’addestramento del modello, testeremo il risultato inserendo un nuovo set di dati, ad esempio Set di dati di prova. Il codice rimane lo stesso tranne alcune piccole modifiche: come x_train e y_train saranno sostituiti da x_test e y_test.
Di seguito è riportato il codice:
Risultato:
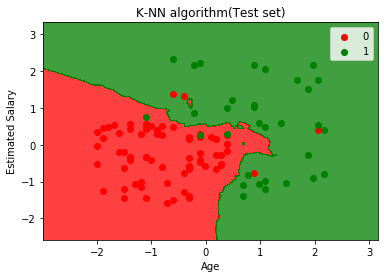
Il grafico sopra mostra l’output per il set di dati di test. Come possiamo vedere nel grafico, l’output previsto è buono buono in quanto la maggior parte dei punti rossi si trova nella regione rossa e la maggior parte dei punti verdi si trova nella regione verde.
Tuttavia, ci sono pochi punti verdi nella regione rossa e alcuni punti rossi nella regione verde. Quindi queste sono le osservazioni errate che abbiamo osservato nella matrice di confusione (7 Output errato).