Come posso trovare valori duplicati in SQL Server?
In questo articolo scopri come trovare valori duplicati in una tabella o vista utilizzando SQL. Andremo passo dopo passo attraverso il processo. Inizieremo con un semplice problema, costruiremo lentamente l’SQL, fino a ottenere il risultato finale.
Alla fine capirai il modello usato per identificare i valori duplicati e sarai in grado di usarlo in database.
Tutti gli esempi di questa lezione si basano su Microsoft SQL Server Management Studio e sul database AdventureWorks2012. Puoi iniziare a utilizzare questi strumenti gratuiti utilizzando la mia Guida introduttiva all’utilizzo di SQL Server.
Trova valori duplicati in SQL Server
Iniziamo. Baseremo questo articolo su una richiesta del mondo reale; il responsabile delle risorse umane vorrebbe che trovassi tutti i dipendenti che condividono lo stesso compleanno. Vorrebbe che l’elenco fosse ordinato per data di nascita e EmployeeName.
Dopo aver esaminato il database, diventa evidente che la tabella HumanResources.Employee è quella da utilizzare poiché contiene le date di nascita dei dipendenti.
a prima vista sembra che sarebbe abbastanza facile trovare valori duplicati in SQL server. Dopotutto possiamo facilmente ordinare i dati.
Ma una volta ordinati i dati diventa più difficile! Poiché SQL è un linguaggio basato su set, non esiste un modo semplice, ad eccezione dell’uso dei cursori, per conoscere i valori del record precedente.
Se li conoscessimo, potremmo semplicemente confrontare i valori e quando erano stesso contrassegna i record come duplicati.
Per fortuna c’è un altro modo per farlo. Useremo un INNER JOIN per abbinare i compleanni dei dipendenti. In questo modo, otterremo un elenco di dipendenti che condividono la stessa data di nascita.
Questo sarà un articolo di costruzione man mano che procedi. Inizierò con una semplice query, mostrerò i risultati e indicherò ciò che deve essere perfezionato e andrò avanti. Inizieremo con un elenco dei dipendenti e delle loro date di nascita.
Passaggio 1: ottieni un elenco dei dipendenti ordinati per data di nascita
Quando si lavora con SQL, specialmente in territori inesplorati, Penso che sia meglio creare un’istruzione in piccoli passaggi, verificando i risultati mentre procedi, piuttosto che scrivere l’SQL “finale” in un unico passaggio, per scoprire che ho solo bisogno di risolverlo.
Suggerimento: se stai lavorando con un database molto grande, quindi potrebbe avere senso fare una copia più piccola come versione di sviluppo o di prova e usarla per scrivere le tue query. In questo modo non interrompi le prestazioni del database di produzione e .
Quindi, per il nostro primo passaggio, elencheremo tutti i dipendenti. Per farlo, uniremo la tabella Employee alla tabella Person per ottenere il nome del dipendente.
Ecco la query fino ad ora
SELECT E1.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
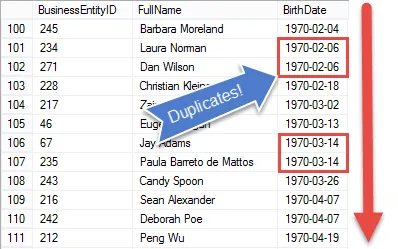
Se guardi il risultato vedrai che abbiamo tutti gli elementi della richiesta del manager delle risorse umane, tranne quello stiamo mostrando ogni dipendente
Nel passaggio successivo imposteremo i risultati in modo da poter iniziare a confrontare le date di nascita per trovare valori duplicati.
PASSAGGIO 2 – Confronta date di nascita per identificare i duplicati.
Ora che abbiamo un elenco di dipendenti, ora abbiamo bisogno di un mezzo per confrontare le date di nascita in modo da poter identificare i dipendenti con le stesse date di nascita. In generale, questi sono valori duplicati.
Per fare il confronto, faremo un auto-join sul tavolo dei dipendenti. Un self-join è solo una versione semplificata di un INNER JOIN. Iniziamo usando BirthDate come condizione di adesione. Ciò garantisce che stiamo recuperando solo dipendenti con la stessa data di nascita.
SELECT E1.BusinessEntityID, E2.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDateORDER BY E1.BirthDate, FullName
Ho aggiunto E2.BusinessEntityID alla query in modo da poter confrontare la chiave primaria di entrambi E1 ed E2. In molti casi si vede che sono uguali.
Il motivo per cui ci stiamo concentrando su BusinessEntityID è che è la chiave primaria e l’identificatore univoco della tabella. Diventa un mezzo molto conciso e conveniente per identificare i risultati di una riga e comprenderne l’origine.
Ci stiamo avvicinando al raggiungimento del nostro risultato finale, ma una volta verificati i risultati vedrai che ” stai raccogliendo lo stesso record sia nella partita E1 che in E2.
Controlla gli elementi cerchiati in rosso. Questi sono i falsi positivi che dobbiamo eliminare dai nostri risultati. Quelle sono le stesse righe che corrispondono a se stesse.
La buona notizia è che siamo davvero vicini all’identificazione dei duplicati.
Ho cerchiato in blu un duplicato garantito al 100%. Notare che i BusinessEntityID sono diversi. Ciò indica che l’autoadesione corrisponde alla data di nascita su righe diverse. Per essere sicuri, sono veri duplicati.
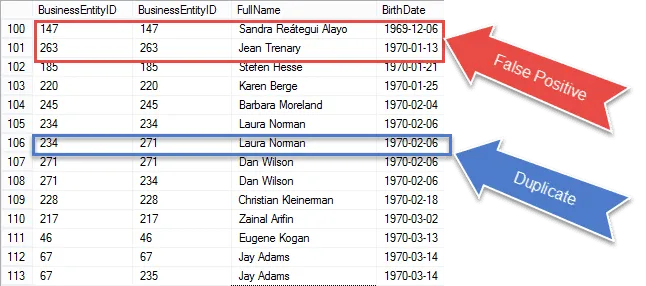
Nel passaggio successivo prenderemo direttamente questi falsi positivi e li rimuoveremo dai nostri risultati.
Passaggio 3 – Elimina corrispondenze nella stessa riga – Rimuovi falsi positivi
Nel passaggio precedente potresti aver notato che tutte le corrispondenze false positive hanno lo stesso BusinessEntityID; mentre i veri duplicati non erano uguali.
Questo è il nostro grande suggerimento.
Se vogliamo vedere solo i duplicati, dobbiamo riportare solo le corrispondenze dal join in cui I valori di BusinessEntityID non sono uguali.
Per fare ciò possiamo aggiungere
E2.BusinessEntityID <> E1.BusinessEntityID
come condizione di join al nostro auto-join. Ho colorato la condizione aggiunta in rosso.
SELECT E1.BusinessEntityID, E2.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Una volta eseguita questa query, vedrai che ci sono meno righe nei risultati e quelle che rimangono sono veramente duplicati.
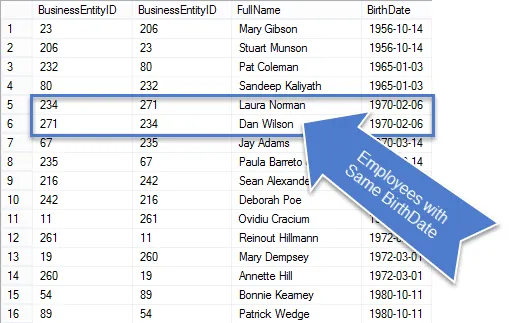
Poiché si trattava di una richiesta commerciale, ripuliamo la query in modo da visualizzare solo le informazioni richieste.
Passaggio 4 – Tocchi finali
Let’s eliminare i valori BusinessEntityID dalla query. Erano lì solo per aiutarci a risolvere i problemi.
La query finale è elencata qui
SELECT P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Ed ecco i risultati a cui puoi presentare il responsabile delle risorse umane!
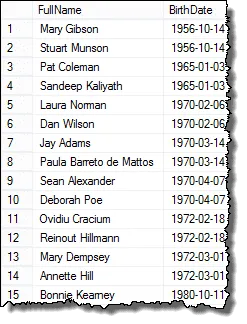
Mark, uno dei miei lettori, mi ha fatto notare che se ci sono tre dipendenti con le stesse date di nascita, avresti duplicati nei risultati finali. Ho verificato questo e questo è vero. Per restituire un elenco che mostra ogni duplicato solo una volta, è possibile utilizzare la clausola DISTINCT. Questa query funziona in tutti i casi:
SELECT DISTINCT P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Commenti finali
Per riepilogare, ecco i passaggi che abbiamo seguito per identificare i dati duplicati nella nostra tabella .
- Per prima cosa abbiamo creato una query dei dati che vogliamo visualizzare. Nel nostro esempio, questo era il dipendente e la sua data di nascita.
- Abbiamo eseguito un auto-join, INNER JOIN sullo stesso tavolo in linguaggio geek e utilizzando il campo che abbiamo ritenuto duplicato. Nel nostro caso volevamo trovare compleanni duplicati.
- Infine abbiamo eliminato le corrispondenze alla stessa riga escludendo le righe in cui le chiavi primarie erano le stesse.
Prendendo un passo dopo passo, puoi vedere che abbiamo impiegato molte supposizioni per creare la query.
Se stai cercando di migliorare il modo in cui scrivi le tue query o sei semplicemente confuso da tutto e stai cercando un modo per cancellare la nebbia, quindi posso suggerire la mia guida Three Steps to Better SQL.