SQL Serverで重複する値を見つけるにはどうすればよいですか?
この記事では、SQLを使用してテーブルまたはビューで重複する値を見つける方法を説明します。プロセスを段階的に進めていきます。単純な問題から始めて、最終結果が得られるまでSQLをゆっくりと構築します。
最後に、重複する値を識別してで使用できるようになるために使用されるパターンを理解します。データベース。
このレッスンのすべての例は、Microsoft SQL Server ManagementStudioとAdventureWorks2012データベースに基づいています。これらの無料ツールの使用を開始するには、ガイド「SQLServer入門ガイド」を使用してください。
SQLServerで重複する値を見つける
始めましょう。この記事は、実際のリクエストに基づいています。人事マネージャーは、すべての従業員が同じ誕生日を共有していることを確認してほしいと考えています。彼女は、リストをBirthDateとEmployeeNameでソートしたいと考えています。
データベースを見ると、HumanResources.Employeeテーブルが従業員の生年月日を含んでいるため使用するテーブルであることがわかります。
At一見すると、SQLサーバーで重複する値を見つけるのは非常に簡単なようです。結局のところ、データは簡単に並べ替えることができます。
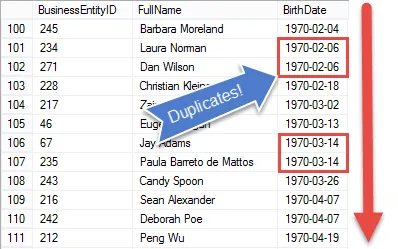
しかし、データが並べ替えられると、難しくなります。 SQLはセットベースの言語であるため、カーソルを使用する以外に、前のレコードの値を知る簡単な方法はありません。
これらを知っていれば、値を比較するだけで、いつそれらが同じようにレコードに重複のフラグを付けます。
幸いなことに、これを行う別の方法があります。従業員の誕生日に合わせて、内部結合を使用します。そうすることで、同じ生年月日を共有している従業員のリストが表示されます。
これは、ビルドとしての記事になります。簡単なクエリから始めて、結果を表示し、改善が必要なものを指摘して次に進みます。まず、従業員とその生年月日のリストを取得します。
ステップ1-生年月日でソートされた従業員のリストを取得する
SQLを使用する場合、特に未知の領域では、トラブルシューティングが必要なのは、「最終的な」SQLを1つのステップで記述するよりも、小さなステップでステートメントを作成し、結果を確認する方がよいと思います。
ヒント:もし非常に大規模なデータベースで作業している場合は、開発バージョンまたはテストバージョンとして小さなコピーを作成し、それを使用してクエリを作成するのが理にかなっている場合があります。
最初のステップとして、すべての従業員を一覧表示します。そのために、EmployeeテーブルをPersonテーブルに結合して、従業員の名前を取得できるようにします。
これまでのクエリです
SELECT E1.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
結果を見ると、HRマネージャーのリクエストのすべての要素があります。すべての従業員を表示しています
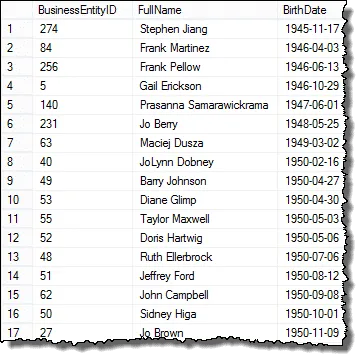
次のステップでは、結果を設定して、生年月日の比較を開始して重複する値を見つけられるようにします。
ステップ2–生年月日を比較して重複を特定します。
これで従業員のリストがあり、同じ生年月日を持つ従業員を識別できるように、生年月日を比較する手段が必要になりました。通常、これらは重複する値です。
比較を行うために、employeeテーブルで自己結合を行います。自己結合は、INNERJOINの単純化されたバージョンです。結合条件としてBirthDateを使用することから始めます。これにより、同じ生年月日を持つ従業員のみを取得できるようになります。
SELECT E1.BusinessEntityID, E2.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDateORDER BY E1.BirthDate, FullName
クエリにE2.BusinessEntityIDを追加して、両方の主キーを比較できるようにしました。 E1およびE2。多くの場合、それらは同じであることがわかります。
BusinessEntityIDに焦点を当てている理由は、それがテーブルの主キーであり一意の識別子であるためです。行の結果を識別し、そのソースを理解するための非常に簡潔で便利な手段になります。
最終結果の取得に近づいていますが、結果を確認すると、次のことがわかります。 E1とE2の両方の試合で同じレコードを再取得します。
赤で囲まれた項目を確認します。これらは、結果から排除する必要のある誤検知です。それらは、それら自体に一致する同じ行です。
幸いなことに、重複を特定するのに非常に近いです。
100%保証された重複を青で囲みました。 BusinessEntityIDが異なることに注意してください。これは、自己結合が異なる行のBirthDateと一致していることを示しています。確かに真の重複です。
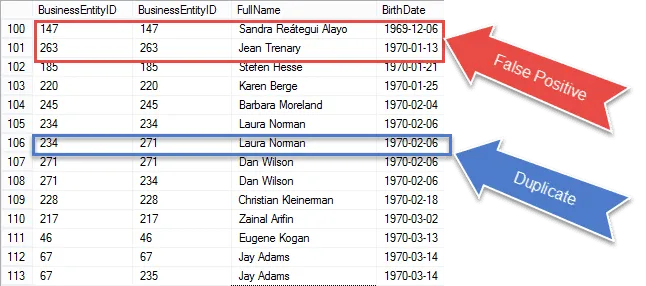
次のステップでは、これらの誤検知を真っ向から取り上げて、結果から削除します。
ステップ3–同じ行への一致を排除する–誤検知を削除する
前のステップで、すべての誤検知の一致が同じBusinessEntityIDを持っていることに気付いたかもしれません。一方、真の重複は等しくありませんでした。
これは私たちの大きなヒントです。
重複のみを表示したい場合は、結合から一致を戻すだけで済みます。 BusinessEntityIDの値が等しくありません。
これを行うには、
E2.BusinessEntityID <> E1.BusinessEntityID
自己結合への結合条件として追加できます。追加した条件を赤で色付けしました。
SELECT E1.BusinessEntityID, E2.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
このクエリを実行すると、結果の行が少なくなり、残っている行が表示されます。本当に重複しています。
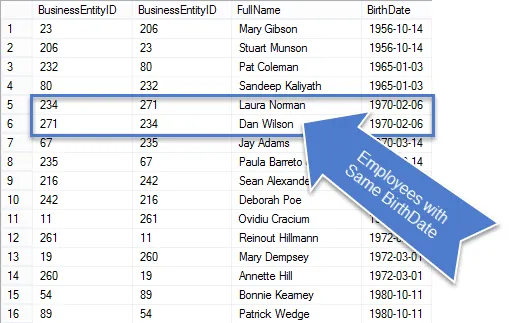
これはビジネスリクエストだったので、クエリをクリーンアップして、リクエストされた情報のみを表示します。
ステップ4–最後の仕上げ
クエリからBusinessEntityID値を削除します。それらはトラブルシューティングを支援するためだけにありました。
最後のクエリはここにリストされています
SELECT P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
そしてここにあなたが提示できる結果があります人事マネージャー!
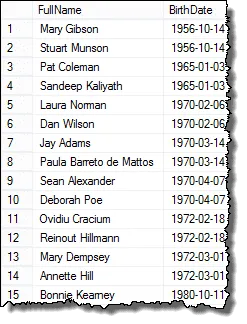
私の読者の1人であるMarkは、同じ誕生日の従業員が3人いると、最終結果が重複することになると指摘しました。私はこれを確認しました、そしてそれは本当です。各重複を1回だけ表示するリストを返すには、DISTINCT句を使用できます。このクエリはすべての場合に機能します。
SELECT DISTINCT P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
最終コメント
要約すると、テーブル内の重複データを特定するために行った手順は次のとおりです。 。
- 最初に、表示するデータのクエリを作成しました。この例では、これは従業員とその生年月日でした。
- オタクの話で同じテーブルで自己結合、INNER JOINを実行し、重複していると見なしたフィールドを使用しました。私たちの場合、重複する誕生日を見つけたいと思いました。
- 最後に、主キーが同じである行を除外することにより、同じ行への一致を排除しました。
ステップバイステップのアプローチでは、クエリの作成から多くの推測作業を行ったことがわかります。
クエリの記述方法を改善したい場合、またはすべてに混乱して探している場合霧を取り除く方法として、SQLを改善するための3つのステップをガイドに提案してもよいでしょうか。