기계 학습을위한 K-Nearest Neighbor (KNN) 알고리즘
- K-Nearest Neighbor는 가장 간단한 기계 학습 알고리즘 중 하나입니다. 지도 학습 기술에 관한 것입니다.
- K-NN 알고리즘은 새로운 사례 / 데이터와 사용 가능한 사례 간의 유사성을 가정하고 사용 가능한 범주와 가장 유사한 범주에 새 사례를 넣습니다.
- K-NN 알고리즘은 사용 가능한 모든 데이터를 저장하고 유사성을 기반으로 새로운 데이터 포인트를 분류합니다. 즉, 새로운 데이터가 나타나면 K-NN 알고리즘을 사용하여 웰 스위트 카테고리로 쉽게 분류 할 수 있습니다.
- K-NN 알고리즘은 분류뿐만 아니라 회귀에도 사용할 수 있지만 대부분 분류 문제에 사용됩니다.
- K-NN은 비모수 알고리즘입니다. 기본 데이터에 대해 어떠한 가정도하지 않습니다.
- 학습 세트에서 즉시 학습하지 않고 데이터 세트를 저장하고 분류시 다음을 수행하기 때문에 지연 학습자 알고리즘이라고도합니다.
- 학습 단계의 KNN 알고리즘은 데이터 세트를 저장하고 새 데이터를 가져 오면 해당 데이터를 새 데이터와 매우 유사한 범주로 분류합니다.
- 예 : 고양이와 개와 비슷해 보이는 생물의 이미지가 있지만 그것이 고양이인지 개인 지 알고 싶다고 가정 해 보겠습니다. 따라서이 식별을 위해 유사성 측정에서 작동하는 KNN 알고리즘을 사용할 수 있습니다. 우리의 KNN 모델은 고양이 및 개 이미지에 대한 새 데이터 세트의 유사한 기능을 찾고 가장 유사한 기능을 기반으로 고양이 또는 개 카테고리에 넣습니다.

K-NN 알고리즘이 필요한 이유는 무엇입니까?
범주 A와 범주 B라는 두 가지 범주가 있고 새로운 데이터 포인트 x1이 있다고 가정합니다. 따라서이 데이터 포인트는 이러한 카테고리 중 어느 것에 속할 것입니다. 이러한 유형의 문제를 해결하려면 K-NN 알고리즘이 필요합니다. K-NN의 도움으로 특정 데이터 세트의 범주 또는 클래스를 쉽게 식별 할 수 있습니다. 아래 다이어그램을 참조하십시오.

K-NN은 어떻게 작동합니까?
K-NN 작동은 다음을 기반으로 설명 될 수 있습니다. 아래 알고리즘 :
- 1 단계 : 이웃 수 K 선택
- 2 단계 : K 이웃 수의 유클리드 거리 계산
- 3 단계 : 계산 된 유클리드 거리에 따라 K 개의 가장 가까운 이웃을 가져옵니다.
- 4 단계 :이 k 개의 이웃 중에서 각 범주의 데이터 포인트 수를 계산합니다.
- 5 단계 : 이웃 수가 최대 인 카테고리에 새 데이터 포인트를 할당합니다.
- 6 단계 : 모델이 준비되었습니다.
새 데이터 포인트가 있고이를 필수 카테고리에 넣어야한다고 가정합니다. 아래 이미지를 살펴보세요.

- 먼저 이웃 수를 선택하므로 k = 5를 선택합니다.
- 다음으로 데이터 포인트 간의 유클리드 거리를 계산합니다. 유클리드 거리는 우리가 이미 기하학에서 공부 한 두 점 사이의 거리입니다. 다음과 같이 계산할 수 있습니다.

- 유클리드 거리를 계산하여 카테고리 A에서 가장 가까운 이웃 3 개를 구했습니다. 카테고리 B의 가장 가까운 이웃 두 개입니다. 아래 이미지를 고려하십시오.

- 우리가 알 수 있듯이 가장 가까운 이웃 3 개가 카테고리에 속합니다. A, 따라서이 새로운 데이터 포인트는 카테고리 A에 속해야합니다.
K-NN 알고리즘에서 K 값을 선택하는 방법
다음은 K-NN 알고리즘에서 K 값을 선택하는 동안 기억하십시오.
- “K”에 대한 최상의 값을 결정하는 특별한 방법이 없으므로 최상의 값을 찾기 위해 몇 가지 값을 시도해야합니다. 그들 중에서. K에 대해 가장 선호되는 값은 5입니다.
- K = 1 또는 K = 2와 같이 K에 대해 매우 낮은 값은 잡음이있을 수 있으며 모델에서 특이 치의 영향으로 이어질 수 있습니다.
- K 값이 크면 좋지만 약간의 어려움이있을 수 있습니다.
KNN 알고리즘의 장점 :
- 구현이 간단합니다.
- 시끄러운 학습 데이터에 견고합니다.
- 학습 데이터가 크면 더 효과적 일 수 있습니다.
KNN 알고리즘의 단점 :
- 항상 복잡 할 수있는 K 값을 결정해야합니다.
- 모든 훈련 샘플에 대한 데이터 포인트 간의 거리를 계산하기 때문에 계산 비용이 높습니다. .
KNN 알고리즘의 Python 구현
K-NN 알고리즘의 Python 구현을 수행하기 위해 우리가 사용한 것과 동일한 문제와 데이터 세트를 사용합니다. 로지스틱 회귀. 그러나 여기서 우리는 모델의 성능을 향상시킬 것입니다. 다음은 문제 설명입니다.
K-NN 알고리즘의 문제 : 새로운 SUV 자동차를 제조 한 자동차 제조업체 회사가 있습니다.회사는 SUV 구매에 관심이있는 사용자에게 광고를 제공하려고합니다. 따라서이 문제에 대해서는 소셜 네트워크를 통해 여러 사용자의 정보를 포함하는 데이터 세트가 있습니다. 데이터 세트에는 많은 정보가 포함되어 있지만 예상 급여 및 연령은 독립 변수에 대해 고려하고 구매 변수는 종속 변수에 대한 것입니다. 다음은 데이터 세트입니다.
K-NN 알고리즘 구현 단계 :
- 데이터 사전 처리 단계
li>
- K-NN 알고리즘을 학습 세트에 맞추기
- 테스트 결과 예측
- 결과의 테스트 정확도 (혼란 행렬 생성)
- 테스트 세트 결과 시각화
데이터 전처리 단계 :
데이터 전처리 단계는 로지스틱 회귀와 정확히 동일하게 유지됩니다. 아래는 코드입니다. 이를 위해 :
위의 코드를 실행하면 데이터 세트를 프로그램으로 가져 와서 잘 전처리합니다. 기능 확장 후 테스트 데이터 세트는 다음과 같습니다.
위의 출력 im 나이에 따라 데이터가 성공적으로 확장되었음을 알 수 있습니다.
- K-NN 분류기를 훈련 데이터에 맞추기 :
이제 K-NN 분류기를 훈련 데이터에 맞출 것입니다. 이를 위해 Sklearn Neighbors 라이브러리의 KNeighborsClassifier 클래스를 가져옵니다. 클래스를 가져온 후 클래스의 Classifier 객체를 생성합니다. 이 클래스의 매개 변수는- n_neighbors : 알고리즘의 필수 인접 항목을 정의합니다. 일반적으로 5가 필요합니다.
- metric = “minkowski”: 기본 매개 변수이며 점 사이의 거리를 결정합니다.
- p = 2 : 표준과 동일합니다. 유클리드 메트릭.
그런 다음 분류기를 훈련 데이터에 맞 춥니 다. 다음은 이에 대한 코드입니다.
출력 : 위 코드를 실행하면 출력이 다음과 같이 표시됩니다.
- 테스트 결과 예측 : 테스트 세트 결과를 예측하기 위해 로지스틱 회귀에서했던 것처럼 y_pred 벡터를 생성합니다. 다음은 이에 대한 코드입니다.
출력 :
위 코드의 출력은 다음과 같습니다.
- 혼동 매트릭스 생성 :
이제 K-NN 모델에 대한 혼동 매트릭스를 생성하여 분류기의 정확도를 확인합니다. 다음은 이에 대한 코드입니다.
위 코드에서 confusion_matrix 함수를 가져와 cm 변수를 사용하여 호출했습니다.
출력 : 위의 코드를 실행하면 다음과 같은 매트릭스를 얻을 수 있습니다.
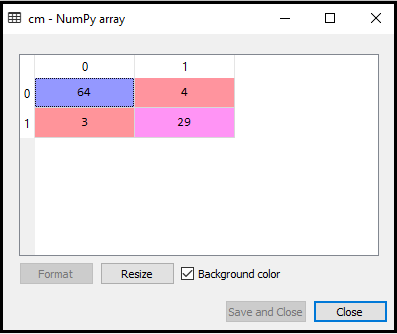
위 이미지에서 64 + 29 = 93 개의 올바른 예측과 3 + 4 = 7 개의 잘못된 예측이있는 반면, 로지스틱 회귀에서는 11 개의 잘못된 예측이있었습니다. 따라서 K-NN 알고리즘을 사용하여 모델의 성능이 향상되었다고 말할 수 있습니다.
- Training set 결과 시각화 :
이제 K에 대한 Training set 결과를 시각화하겠습니다. -NN 모델. 코드는 그래프의 이름을 제외하고 Logistic Regression에서했던 것과 동일하게 유지됩니다. 다음은 이에 대한 코드입니다.
출력 :
위 코드를 실행하면 아래 그래프가 표시됩니다.
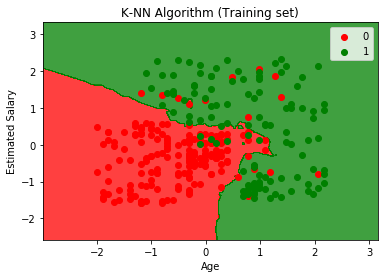
출력 그래프는 로지스틱 회귀에서 발생한 그래프와 다릅니다. 아래 지점에서 이해할 수 있습니다.
- 그래프가 빨간색 점과 녹색 점을 표시하는 것을 볼 수 있습니다. 녹색 포인트는 Purchased (1)에 대한 것이고 Red Point는 Purchased (0) 변수가 아닌 것에 대한 것입니다.
- K-NN 알고리즘, 즉 가장 가까운 이웃을 찾기 때문에 그래프는 직선이나 곡선을 표시하는 대신 불규칙한 경계를 표시합니다.
- SUV를 구매하지 않은 대부분의 사용자는 빨간색 영역에 있고 SUV를 구매 한 사용자는 녹색 영역에 있으므로 그래프는 올바른 카테고리로 사용자를 분류했습니다.
- 그래프는 좋은 결과를 보여주고 있지만 여전히 빨간색 영역에 녹색 점이 있고 녹색 영역에 빨간색 점이 있습니다.하지만이 모델을 수행하면 과적 합 문제가 방지되므로 큰 문제가 아닙니다.
- 따라서 모델이 잘 훈련되었습니다.
- 테스트 세트 결과 시각화 :
모델 학습 후 이제 새 데이터 세트를 넣어 결과를 테스트합니다. 테스트 데이터 세트입니다. 코드는 약간의 변경 사항을 제외하고는 동일합니다. 예를 들어 x_train 및 y_train은 x_test 및 y_test로 대체됩니다.
다음은 해당 코드입니다.
출력 :
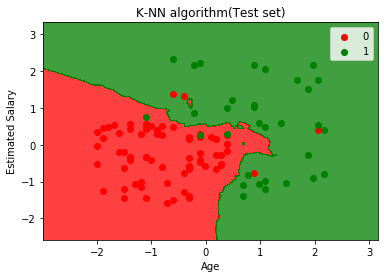
위 그래프는 테스트 데이터 세트의 출력을 보여줍니다. 그래프에서 볼 수 있듯이 예상 출력은 양호합니다. 대부분의 빨간색 점이 빨간색 영역에 있고 대부분의 녹색 점은 녹색 영역에 있습니다.
그러나 빨간색 영역에는 녹색 점이 거의없고 녹색 영역에는 몇 개의 빨간색 점이 있습니다. 그래서 이것은 우리가 혼동 행렬에서 관찰 한 잘못된 관찰입니다 (7 잘못된 출력).