Hvordan kan jeg finne dupliserte verdier i SQL Server?
I denne artikkelen kan du finne ut hvordan du finner dupliserte verdier i en tabell eller visning ved hjelp av SQL. Vi går trinn for trinn gjennom prosessen. Vi begynner med et enkelt problem, sakte bygger opp SQL til vi oppnår sluttresultatet.
Til slutt vil du forstå mønsteret som brukes til å identifisere dupliserte verdier og være i stand til å bruke i databasen din.
Alle eksemplene for denne leksjonen er basert på Microsoft SQL Server Management Studio og AdventureWorks2012-databasen. Du kan komme i gang med disse gratisverktøyene ved å bruke guiden min Komme i gang med SQL Server.
Finn dupliserte verdier i SQL Server
La oss komme i gang. Vi baserer denne artikkelen på en forespørsel fra den virkelige verden; personalsjefen vil at du skal finne alle ansatte som deler samme bursdag. Hun vil at listen skal være sortert etter BirthDate og EmployeeName.
Etter å ha sett på databasen, blir det tydelig at HumanResources.Tabell for medarbeidere er den som skal brukes da den inneholder fødselsdatoer for ansatte.
På ved første øyekast virker det som om det ville være ganske enkelt å finne dupliserte verdier i SQL server. Vi kan tross alt enkelt sortere dataene.
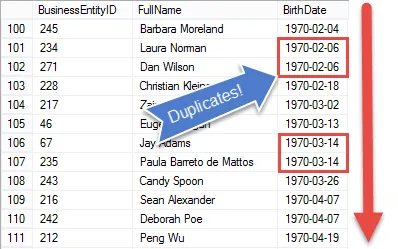
Men når dataene er sortert, blir det vanskeligere! Siden SQL er et settbasert språk, er det ikke en enkel måte, bortsett fra å bruke markører, å kjenne den forrige postens verdier.
Hvis vi visste disse, kunne vi bare sammenligne verdier, og når de var samme flagg postene som duplikater.
Heldigvis er det en annen måte for oss å gjøre dette på. Vi bruker en INNER JOIN for å matche medarbeidernes fødselsdager. Ved å gjøre dette får vi en liste over ansatte som deler samme fødselsdato.
Dette kommer til å være en artikkel om hvordan du bygger opp. Jeg begynner med et enkelt spørsmål, viser resultater og peker på hva som trenger forbedring og går videre. Vi starter med å få en liste over ansatte og fødselsdatoer.
Trinn 1 – Få en liste over ansatte sortert etter fødselsdato
Når du arbeider med SQL, spesielt i ukartet territorium, Jeg føler det er bedre å lage en uttalelse i små trinn, og verifisere resultatene mens du går, i stedet for å skrive den «endelige» SQL i ett trinn, for bare å finne at jeg trenger å feilsøke den.
Tips: Hvis du jobber med en veldig stor database, da kan det være fornuftig å lage en mindre kopi som din dev- eller testversjon og bruke den til å skrive spørsmålene dine. På den måten dreper du ikke ytelsen til produksjonsdatabasen og får alle ned på deg.
Så for det første trinnet, skal vi liste opp alle ansatte. For å gjøre det, vil vi bli med Ansatt-tabellen til persontabellen for å få navnet på den ansatte.
Her er spørringen så langt
SELECT E1.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Hvis du ser på resultatet ser du at vi har alle elementene i HR-sjefens forespørsel, bortsett fra at vi viser hver ansatt
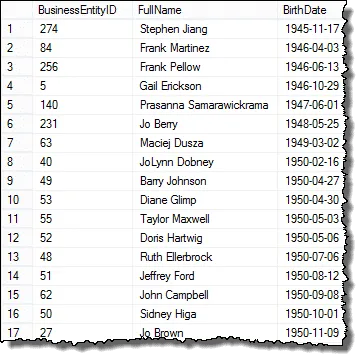
I neste trinn vil vi sette opp resultatene slik at vi kan begynne å sammenligne fødselsdatoer for å finne dupliserte verdier.
TRINN 2 – Sammenlign fødselsdatoer for å identifisere duplikater.
Nå som vi har en liste over ansatte vi nå trenger et middel til å sammenligne fødselsdatoer slik at vi kan identifisere ansatte med samme fødselsdato. Generelt sett er dette dupliserte verdier.
For å gjøre sammenligningen vil vi gjøre en selvtilknytning på arbeidstakerbordet. En selvtilslutning er bare en forenklet versjon av en INNER JOIN. Vi begynner å bruke BirthDate som vår tilstand. Dette sikrer at vi bare henter ansatte med samme fødselsdato.
SELECT E1.BusinessEntityID, E2.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDateORDER BY E1.BirthDate, FullName
Jeg la til E2.BusinessEntityID i spørringen, slik at du kan sammenligne primærnøkkelen fra begge E1 og E2. Du ser i mange tilfeller at de er de samme.
Årsaken til at vi fokuserer på BusinessEntityID er at den er den primære nøkkelen og den unike identifikatoren for tabellen. Det blir et veldig kortfattet og praktisk middel til å identifisere en rads resultater og forstå kilden.
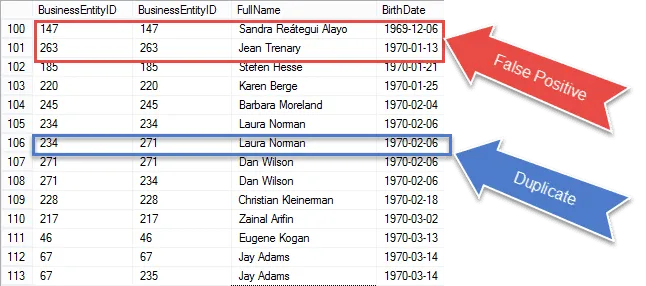
Vi kommer nærmere vårt endelige resultat, men når du sjekker ut resultatene, ser vi re plukker opp den samme posten i både E1 og E2 match.
Sjekk ut varene som er sirklet i rødt. Det er de falske positive vi må eliminere fra resultatene. Det er de samme radene som samsvarer med seg selv.
Den gode nyheten er at vi er veldig nær å bare identifisere duplikatene.
Jeg sirklet et 100% garantert duplikat i blått. Legg merke til at BusinessEntityID er forskjellige. Dette indikerer at selvtilslutningen samsvarer med fødselsdatoen på forskjellige rader – ekte duplikater for å være sikker.
I neste trinn tar vi falske positive på hodet og fjerner dem fra resultatene våre.
Trinn 3 – Eliminer treff til samme rad – Fjern falske positive
I det forrige trinnet har du kanskje lagt merke til at alle falske positive treff har samme BusinessEntityID; mens de sanne duplikatene ikke var like.
Dette er vårt store hint.
Hvis vi bare vil se duplikater, trenger vi bare å bringe tilbake kamper fra sammenføyningen der BusinessEntityID-verdiene er ikke like.
For å gjøre dette kan vi legge til
E2.BusinessEntityID <> E1.BusinessEntityID
Som en sammenføyningsbetingelse for vår selvtilslutning. Jeg har farget den tilførte tilstanden i rødt.
SELECT E1.BusinessEntityID, E2.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Når dette spørsmålet er kjørt, ser du at det er færre rader i resultatene, og de som gjenstår er virkelig duplikater.
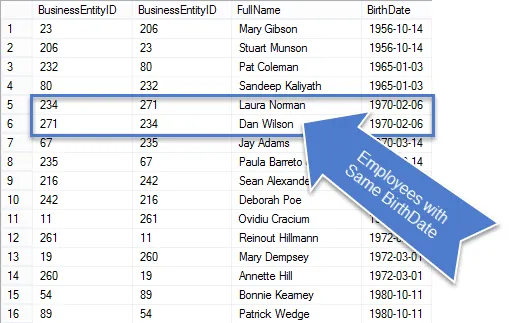
Siden dette var en forretningsforespørsel, la oss rydde opp i spørringen, slik at vi bare viser den etterspurte informasjonen.
Trinn 4 – siste grep
La oss kvitt BusinessEntityID-verdiene fra spørringen. De var der bare for å hjelpe oss med å feilsøke.
Det endelige spørsmålet er oppført her
SELECT P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Og her er resultatene du kan presentere for HR-sjefen!
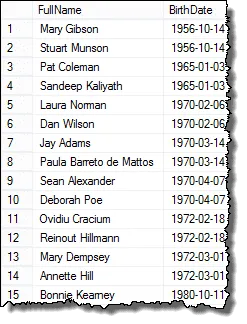
Mark, en av leserne mine, påpekte meg at hvis det er tre ansatte som har samme fødselsdato, vil du ha duplikater i de endelige resultatene. Jeg bekreftet dette og det er sant. For å returnere en liste som viser hvert duplikat bare én gang, kan du bruke DISTINCT-setningen. Dette spørsmålet fungerer i alle tilfeller:
SELECT DISTINCT P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Endelige kommentarer
For å oppsummere her er trinnene vi tok for å identifisere duplikatdata i tabellen vår .
- Vi opprettet først et spørsmål om dataene vi vil se. I vårt eksempel var dette den ansatte og fødselsdatoen deres.
- Vi utførte en selvtilslutning, INNER JOIN på samme bord i geek speak, og brukte feltet vi anså som duplikat. I vårt tilfelle ønsket vi å finne dupliserte fødselsdager.
- Til slutt fjernet vi treff til samme rad ved å ekskludere rader der primærnøklene var de samme.
Ved å ta en trinnvis tilnærming kan du se at vi tok mye av gjetningsarbeidet med å lage spørringen.
Hvis du ønsker å forbedre hvordan du skriver spørsmålene dine eller bare blir forvirret av det hele og leter etter en måte å tåke tåken på, så kan jeg foreslå min guide Three Steps to Better SQL.