Hoe kan ik dubbele waarden vinden in SQL Server?
In dit artikel leest u hoe u dubbele waarden in een tabel of weergave kunt vinden met behulp van SQL. We doorlopen het proces stap voor stap. We beginnen met een eenvoudig probleem, bouwen langzaam de SQL op totdat we het eindresultaat bereiken.
Aan het einde begrijp je het patroon dat wordt gebruikt om dubbele waarden te identificeren en te gebruiken in in uw database.
Alle voorbeelden voor deze les zijn gebaseerd op Microsoft SQL Server Management Studio en de AdventureWorks2012-database. U kunt aan de slag met deze gratis tools met behulp van mijn Gids Aan de slag met SQL Server.
Dubbele waarden zoeken in SQL Server
Laten we beginnen. We baseren dit artikel op een verzoek uit de echte wereld; de human resource manager wil dat u alle medewerkers opzoekt die dezelfde verjaardag delen. Ze wil de lijst gesorteerd op geboortedatum en werknemer-naam.
Na het bekijken van de database wordt het duidelijk dat de tabel HumanResources.Employee degene is die moet worden gebruikt, aangezien deze de geboortedata van de werknemer bevat.
Op Op het eerste gezicht lijkt het vrij eenvoudig om dubbele waarden in SQL Server te vinden. We kunnen de gegevens tenslotte gemakkelijk sorteren.
Maar zodra de gegevens zijn gesorteerd, wordt het moeilijker! Aangezien SQL een set-gebaseerde taal is, is er geen gemakkelijke manier, behalve door cursors te gebruiken, om de waarden van het vorige record te kennen.
Als we deze wisten, zouden we gewoon waarden kunnen vergelijken, en wanneer ze de same markeert de records als duplicaten.
Gelukkig is er voor ons een andere manier om dit te doen. We gebruiken een INNER JOIN om verjaardagen van medewerkers te matchen. Door dit te doen, krijgen we een lijst met werknemers met dezelfde geboortedatum.
Dit wordt een build-as-you-go-artikel. Ik begin met een simpele vraag, laat resultaten zien, geef aan wat verfijning nodig heeft en ga verder. We beginnen met het opvragen van een lijst met werknemers en hun geboortedata.
Stap 1 – Ontvang een lijst met werknemers gesorteerd op geboortedatum
Wanneer u met SQL werkt, vooral in onbekend terrein, Ik denk dat het beter is om een verklaring in kleine stappen op te bouwen en de resultaten gaandeweg te verifiëren, in plaats van de “laatste” SQL in één stap te schrijven, om erachter te komen dat ik het probleem moet oplossen.
Hint: als u werkt met een zeer grote database, dan kan het zinvol zijn om een kleinere kopie te maken als uw ontwikkel- of testversie en die te gebruiken om uw vragen te schrijven. Op die manier vernietigt u de prestaties van de productiedatabase niet en krijgt iedereen u.
Dus voor onze eerste stap gaan we alle medewerkers opsommen. Om dit te doen, voegen we ons aan de Medewerkerstafel bij de Persoonstabel zodat we de naam van de medewerker kunnen krijgen.
Hier is de vraag tot dusver
SELECT E1.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
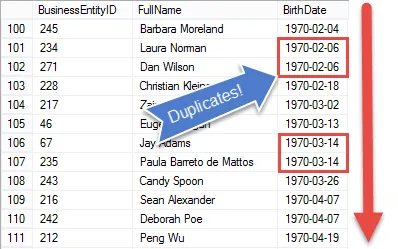
Als je naar het resultaat kijkt, zie je dat we alle elementen van het verzoek van de HR-manager hebben, behalve dat we tonen elke medewerker
In de volgende stap stellen we de resultaten op, zodat we geboortedata kunnen vergelijken om dubbele waarden te vinden.
STAP 2 – Vergelijk geboortedata om duplicaten te identificeren.
Nu dat we hebben een lijst met werknemers, we hebben nu een manier nodig om geboortedata te vergelijken, zodat we werknemers met dezelfde geboortedata kunnen identificeren. Over het algemeen zijn dit dubbele waarden.
Om de vergelijking te doen, doen we een self-join aan de medewerkerstafel. Een self-join is slechts een vereenvoudigde versie van een INNER JOIN. We beginnen met BirthDate als onze voorwaarde voor deelname. Dit zorgt ervoor dat we alleen werknemers ophalen met dezelfde geboortedatum.
SELECT E1.BusinessEntityID, E2.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDateORDER BY E1.BirthDate, FullName
Ik heb E2.BusinessEntityID aan de zoekopdracht toegevoegd, zodat je de primaire sleutel van beide kunt vergelijken E1 en E2. U ziet in veel gevallen dat ze hetzelfde zijn.
De reden dat we ons richten op BusinessEntityID is dat dit de primaire sleutel en de unieke identificatiecode voor de tabel is. Het wordt een zeer beknopt en handig middel om de resultaten van een rij te identificeren en de bron ervan te begrijpen.
We komen dichter bij het verkrijgen van ons eindresultaat, maar zodra u de resultaten bekijkt, zult u zien dat we ‘ herhalen van hetzelfde record in zowel de E1- als de E2-wedstrijd.
Bekijk de items die in rood zijn omcirkeld. Dat zijn de valse positieven die we uit onze resultaten moeten verwijderen. Dat zijn dezelfde rijen die bij elkaar passen.
Het goede nieuws is dat we bijna de duplicaten hebben geïdentificeerd.
Ik heb een 100% gegarandeerd duplicaat in blauw omcirkeld. Merk op dat de BusinessEntityID’s verschillend zijn. Dit geeft aan dat de self-join overeenkomt met BirthDate op verschillende rijen – echte duplicaten om zeker te zijn.
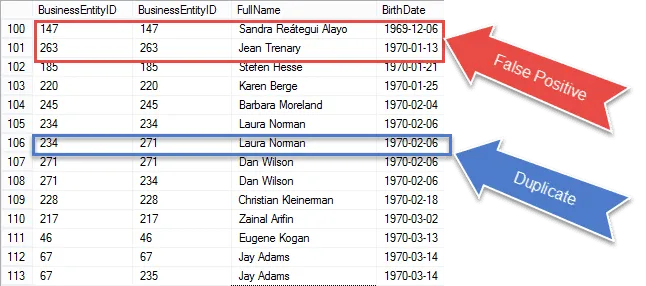
In de volgende stap nemen we die fout-positieven direct door en verwijderen we ze uit onze resultaten.
Stap 3 – Elimineer overeenkomsten naar dezelfde rij – Verwijder valse positieven
In de vorige stap is het je misschien opgevallen dat alle valse positieve overeenkomsten dezelfde BusinessEntityID hebben; terwijl de echte duplicaten niet gelijk waren.
Dit is onze grote hint.
Als we alleen duplicaten willen zien, dan hoeven we alleen matches terug te halen van de join waar de BusinessEntityID-waarden zijn niet gelijk.
Om dit te doen kunnen we
E2.BusinessEntityID <> E1.BusinessEntityID
toevoegen als een voorwaarde voor samenvoegen aan onze self-join. Ik heb de toegevoegde voorwaarde rood gekleurd.
SELECT E1.BusinessEntityID, E2.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Zodra deze zoekopdracht is uitgevoerd, ziet u dat er minder rijen in de resultaten zijn en de rijen die overblijven zijn echt duplicaten.
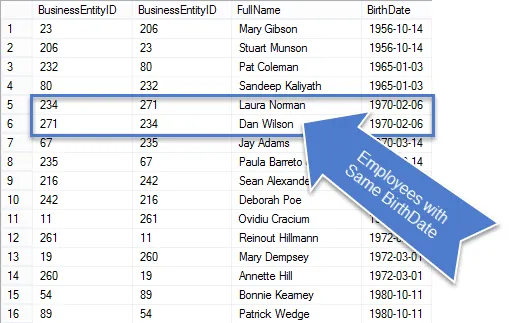
Aangezien dit een zakelijk verzoek was, laten we de zoekopdracht opschonen zodat we alleen de gevraagde informatie tonen.
Stap 4 – Laatste hand.
Laten we verwijder de BusinessEntityID-waarden uit de query. Ze waren er alleen om ons te helpen bij het oplossen van problemen.
De laatste vraag wordt hier vermeld
SELECT P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
En hier zijn de resultaten die u kunt presenteren aan de HR-manager!
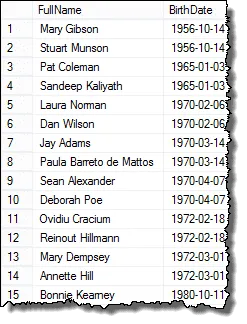
Mark, een van mijn lezers, wees me erop dat als er drie werknemers zijn met dezelfde geboortedatum, je duplicaten zou hebben in de eindresultaten. Ik heb dit geverifieerd en dat is waar. Om een lijst te retourneren, toon elk duplicaat maar één keer, u kunt de DISTINCT-clausule gebruiken. Deze zoekopdracht werkt in alle gevallen:
SELECT DISTINCT P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Laatste opmerkingen
Om hier samen te vatten zijn de stappen die we hebben genomen om dubbele gegevens in onze tabel te identificeren .
- We hebben eerst een zoekopdracht gemaakt met de gegevens die we willen bekijken. In ons voorbeeld was dit de werknemer en hun geboortedatum.
- We voerden een self-join uit, INNER JOIN op dezelfde tafel in geek-speak, en met behulp van het veld beschouwden we als een duplicaat. In ons geval wilden we dubbele verjaardagen vinden.
- Ten slotte hebben we overeenkomsten met dezelfde rij verwijderd door rijen uit te sluiten waarin de primaire sleutels hetzelfde waren.
Door een stap voor stap benadering, u kunt zien dat we veel giswerk hebben weggenomen bij het maken van de zoekopdracht.
Als u de manier waarop u uw vragen schrijft wilt verbeteren of als u er gewoon door in de war raakt en op zoek bent naar een manier om de mist te verwijderen, dan kan ik mijn gids Three Steps to Better SQL voorstellen.