K-dichtstbijzijnde buur (KNN) algoritme voor machine learning
- K-dichtstbijzijnde buur is een van de eenvoudigste machine learning-algoritmen op Supervised Learning-techniek.
- Het K-NN-algoritme gaat uit van de gelijkenis tussen de nieuwe case / data en beschikbare cases en plaatst de nieuwe case in de categorie die het meest lijkt op de beschikbare categorieën.
- K-NN-algoritme slaat alle beschikbare gegevens op en classificeert een nieuw gegevenspunt op basis van de gelijkenis. Dit betekent dat wanneer er nieuwe gegevens verschijnen, deze gemakkelijk kunnen worden geclassificeerd in een categorie van bronnen met behulp van het K-NN-algoritme.
- K-NN-algoritme kan zowel voor regressie als voor classificatie worden gebruikt, maar wordt meestal gebruikt voor classificatieproblemen.
- K-NN is een niet-parametrisch algoritme, wat betekent het doet geen veronderstellingen over de onderliggende gegevens.
- Het wordt ook wel een luie leerling-algoritme genoemd, omdat het niet onmiddellijk leert van de trainingsset, maar de dataset opslaat en op het moment van classificatie een actie op de dataset.
- Het KNN-algoritme slaat tijdens de trainingsfase alleen de dataset op en wanneer het nieuwe data krijgt, classificeert het die data in een categorie die veel lijkt op de nieuwe data.
- Voorbeeld: stel dat we een afbeelding hebben van een wezen dat lijkt op een kat en een hond, maar we willen weten of het een kat of een hond is. Dus voor deze identificatie kunnen we het KNN-algoritme gebruiken, omdat het werkt op een gelijkenismaat. Ons KNN-model zal de vergelijkbare kenmerken van de nieuwe dataset vinden als de afbeeldingen van katten en honden en op basis van de meest vergelijkbare kenmerken zal het in de categorie kat of hond worden geplaatst.

Waarom hebben we een K-NN-algoritme nodig?
Stel dat er twee categorieën zijn, namelijk categorie A en categorie B, en we hebben een nieuw datapunt x1, dus dit datapunt zal in welke van deze categorieën vallen. Om dit soort problemen op te lossen, hebben we een K-NN-algoritme nodig. Met behulp van K-NN kunnen we gemakkelijk de categorie of klasse van een bepaalde dataset identificeren. Beschouw het onderstaande diagram:

Hoe werkt K-NN?
De werking van K-NN kan worden verklaard aan de hand van het onderstaande algoritme:
- Stap-1: Selecteer het aantal K van de buren
- Stap-2: Bereken de Euclidische afstand van K aantal buren
- Stap-3: neem de K dichtstbijzijnde buren volgens de berekende Euclidische afstand.
- Stap-4: tel onder deze k buren het aantal datapunten in elke categorie.
- Stap-5: wijs de nieuwe datapunten toe aan die categorie waarvoor het nummer van de buur maximaal is.
- Stap-6: ons model is klaar.
Stel dat we een nieuw datapunt hebben en dat we het in de vereiste categorie moeten plaatsen. Beschouw de onderstaande afbeelding:

- Ten eerste zullen we het aantal buren kiezen, dus we zullen de k = 5 kiezen.
- Vervolgens zullen we de Euclidische afstand tussen de gegevenspunten berekenen. De Euclidische afstand is de afstand tussen twee punten, die we al in de meetkunde hebben bestudeerd. Het kan worden berekend als:

- Door de Euclidische afstand te berekenen hebben we de dichtstbijzijnde buren, als drie naaste buren in categorie A en twee naaste buren in categorie B. Beschouw de onderstaande afbeelding:

- Zoals we kunnen zien, zijn de 3 naaste buren van categorie A, vandaar dat dit nieuwe gegevenspunt tot categorie A moet behoren.
Hoe de waarde van K in het K-NN-algoritme selecteren?
Hieronder staan enkele punten om onthoud bij het selecteren van de waarde van K in het K-NN-algoritme:
- Er is geen specifieke manier om de beste waarde voor “K” te bepalen, dus we moeten enkele waarden proberen om de beste te vinden uit hen. De meest geprefereerde waarde voor K is 5.
- Een zeer lage waarde voor K, zoals K = 1 of K = 2, kan luidruchtig zijn en leiden tot de effecten van uitschieters in het model.
- Grote waarden voor K zijn goed, maar het kan enkele problemen opleveren.
Voordelen van KNN-algoritme:
- Het is eenvoudig te implementeren.
- Het is robuust voor de luidruchtige trainingsgegevens
- Het kan effectiever zijn als de trainingsgegevens groot zijn.
Nadelen van KNN-algoritme:
- Moet altijd de waarde van K bepalen, wat op een gegeven moment complex kan zijn.
- De berekeningskosten zijn hoog vanwege het berekenen van de afstand tussen de datapunten voor alle trainingsmonsters .
Python-implementatie van het KNN-algoritme
Om de Python-implementatie van het K-NN-algoritme uit te voeren, zullen we hetzelfde probleem en dezelfde dataset gebruiken die we hebben gebruikt in Logistieke regressie. Maar hier zullen we de prestaties van het model verbeteren. Hieronder staat de probleembeschrijving:
Probleem voor K-NN-algoritme: er is een autofabrikant die een nieuwe SUV-auto heeft geproduceerd.Het bedrijf wil de advertenties geven aan de gebruikers die geïnteresseerd zijn in het kopen van die SUV. Dus voor dit probleem hebben we een dataset die informatie over meerdere gebruikers bevat via het sociale netwerk. De dataset bevat veel informatie, maar het geschatte salaris en de leeftijd zullen we in overweging nemen voor de onafhankelijke variabele en de gekochte variabele is voor de afhankelijke variabele. Hieronder vindt u de dataset:
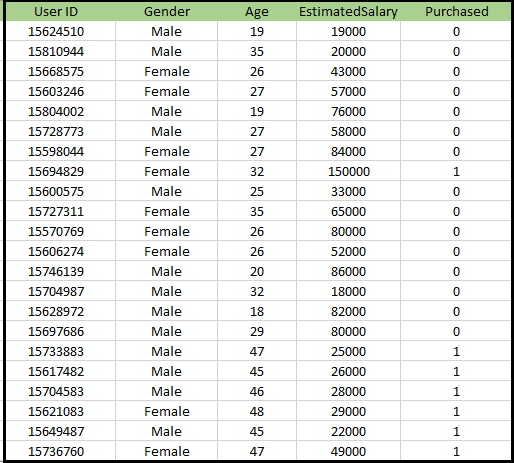
Stappen om het K-NN-algoritme te implementeren:
- Stap voor gegevensvoorbewerking
- Het K-NN-algoritme aanpassen aan de trainingsset
- Het testresultaat voorspellen
- Nauwkeurigheid van het resultaat testen (Creation of Confusion matrix)
- Visualiseren van het resultaat van de testset.
Stap voor gegevensvoorverwerking:
De stap voor gegevensvoorverwerking blijft exact hetzelfde als Logistieke regressie. Hieronder vindt u de code ervoor:
Door de bovenstaande code uit te voeren, wordt onze dataset in ons programma geïmporteerd en goed voorverwerkt. Na het schalen van features ziet onze testdataset er als volgt uit:
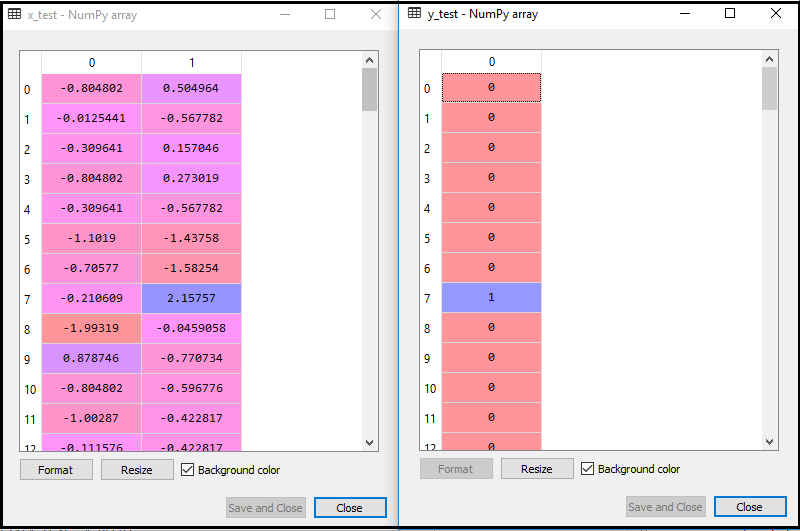
Van de bovenstaande uitvoer im leeftijd, kunnen we zien dat onze gegevens met succes zijn geschaald.
- K-NN-classificator aanpassen aan de trainingsgegevens:
Nu gaan we de K-NN-classificatie aanpassen aan de trainingsgegevens. Om dit te doen zullen we de klasse KNeighboursClassifier van de bibliotheek Sklearn Neighbours importeren. Na het importeren van de klasse, maken we het Classifier-object van de klasse. De parameter van deze klasse is- n_neighbours: om de vereiste neighbours van het algoritme te definiëren. Meestal duurt het 5.
- metric = “minkowski”: dit is de standaardparameter en het bepaalt de afstand tussen de punten.
- p = 2: het is gelijk aan de standaard Euclidische metriek.
En dan passen we de classificator aan de trainingsgegevens aan. Hieronder staat de code ervoor:
Output: door de bovenstaande code uit te voeren, krijgen we de output als:
- Het testresultaat voorspellen: Om het resultaat van de testset te voorspellen, zullen we een y_pred-vector maken zoals we deden in Logistic Regression. Hieronder staat de code ervoor:
Output:
De output voor de bovenstaande code zal zijn:
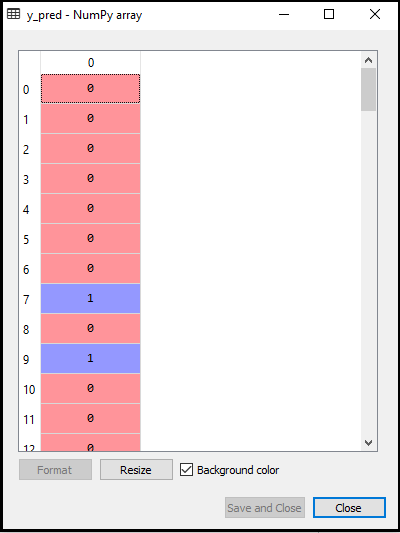
- De verwarringmatrix maken:
Nu gaan we de verwarringmatrix voor ons K-NN-model maken om de nauwkeurigheid van de classificatie te zien. Hieronder staat de code ervoor:
In bovenstaande code hebben we de confusion_matrix-functie geïmporteerd en deze aangeroepen met behulp van de variabele cm.
Uitvoer: door de bovenstaande code uit te voeren, krijgen we de onderstaande matrix:
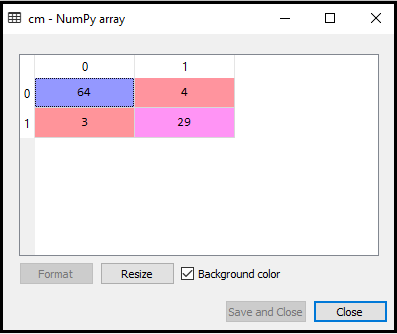
In de bovenstaande afbeelding kunnen we zien er zijn 64 + 29 = 93 correcte voorspellingen en 3 + 4 = 7 onjuiste voorspellingen, terwijl er in Logistic Regression 11 onjuiste voorspellingen waren. We kunnen dus zeggen dat de prestaties van het model zijn verbeterd door het K-NN-algoritme te gebruiken.
- Het resultaat van de trainingsset visualiseren:
Nu zullen we het resultaat van de trainingsset voor K -NN-model. De code blijft hetzelfde als in Logistic Regression, behalve de naam van de grafiek. Hieronder staat de code ervoor:
Uitvoer:
Door de bovenstaande code uit te voeren, krijgen we de onderstaande grafiek:
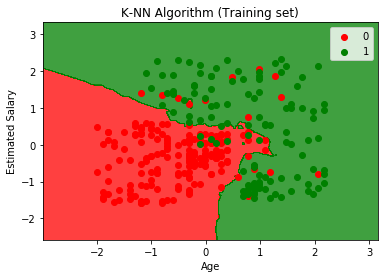
De uitvoergrafiek verschilt van de grafiek die we hebben voorgedaan in Logistic Regression. Het kan worden begrepen in de onderstaande punten:
- Zoals we kunnen zien, toont de grafiek het rode punt en de groene punten. De groene punten zijn voor gekocht (1) en rode punten voor niet gekocht (0) variabele.
- De grafiek toont een onregelmatige grens in plaats van een rechte lijn of een curve te tonen, omdat het een K-NN-algoritme is, d.w.z. het vinden van de dichtstbijzijnde buur.
- De grafiek heeft gebruikers in de juiste categorieën ingedeeld, aangezien de meeste gebruikers die de SUV niet hebben gekocht zich in de rode regio bevinden en gebruikers die de SUV hebben gekocht zich in de groene regio.
- De grafiek laat een goed resultaat zien, maar toch zijn er enkele groene punten in het rode gebied en rode punten in het groene gebied. Maar dit is geen groot probleem, want door dit model te doen, worden problemen met overfitting voorkomen.
- Daarom is ons model goed getraind.
- Visualiseren van het resultaat van de testset:
Na de training van het model zullen we het resultaat testen door een nieuwe dataset te plaatsen, dwz Testdataset. Code blijft hetzelfde, behalve enkele kleine wijzigingen: zoals x_train en y_train worden vervangen door x_test en y_test.
Hieronder staat de code ervoor:
Uitvoer:
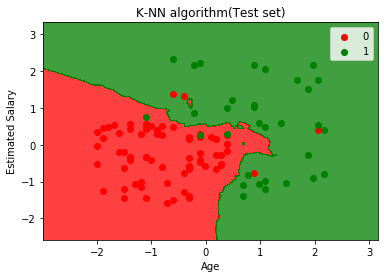
De bovenstaande grafiek toont de uitvoer voor de testgegevensset. Zoals we in de grafiek kunnen zien, is de voorspelde uitvoer goed goed aangezien de meeste rode punten in het rode gebied en de meeste groene punten bevinden zich in de groene regio.
Er zijn echter enkele groene punten in de rode regio en een paar rode punten in de groene regio. Dit zijn dus de onjuiste waarnemingen die we hebben waargenomen in de verwarringmatrix (7 Incorrecte uitvoer).