Jak znaleźć zduplikowane wartości w programie SQL Server?
W tym artykule dowiesz się, jak znaleźć zduplikowane wartości w tabeli lub widoku za pomocą języka SQL. Przejdziemy przez ten proces krok po kroku. Zaczniemy od prostego problemu, powoli rozbudowujemy SQL, aż osiągniemy wynik końcowy.
Pod koniec zrozumiesz wzorzec używany do identyfikowania zduplikowanych wartości i będziesz mógł używać ich w twoją bazę danych.
Wszystkie przykłady w tej lekcji są oparte na Microsoft SQL Server Management Studio i bazie danych AdventureWorks2012. Możesz zacząć korzystać z tych bezpłatnych narzędzi, korzystając z mojego Przewodnika Pierwsze kroki z SQL Server.
Znajdź zduplikowane wartości w SQL Server
Zaczynajmy. Opieramy ten artykuł na prawdziwym żądaniu; kierownik działu kadr chciałby, abyś znalazł wszystkich pracowników, którzy obchodzą te same urodziny. Chciałaby, aby lista była posortowana według daty urodzenia i nazwiska pracownika.
Po przejrzeniu bazy danych okazuje się, że należy użyć tabeli Zasoby ludzkie. Pracownik, ponieważ zawiera ona daty urodzenia pracowników.
At na pierwszy rzut oka wydaje się, że byłoby całkiem łatwo znaleźć zduplikowane wartości na serwerze SQL. W końcu możemy łatwo sortować dane.
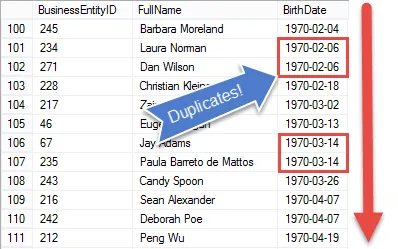
Ale posortowanie danych staje się trudniejsze! Ponieważ SQL jest językiem opartym na zbiorach, nie ma łatwego sposobu, poza użyciem kursorów, aby poznać wartości poprzedniego rekordu.
Gdybyśmy je znali, moglibyśmy po prostu porównać wartości, a kiedy byłyby tak samo oznaczaj rekordy jak duplikaty.
Na szczęście istnieje inny sposób, aby to zrobić. Użyjemy INNER JOIN, aby dopasować urodziny pracowników. W ten sposób otrzymamy listę pracowników o tej samej dacie urodzenia.
To będzie artykuł na bieżąco. Zacznę od prostego zapytania, pokażę wyniki, wskażę, co wymaga doprecyzowania, i przejdę dalej. Zaczniemy od uzyskania listy pracowników i ich dat urodzenia.
Krok 1 – Uzyskaj listę pracowników posortowaną według daty urodzenia
Podczas pracy z SQL, szczególnie na nieznanym terytorium, Uważam, że lepiej jest budować instrukcję małymi krokami, weryfikując wyniki na bieżąco, zamiast pisać „ostateczną” instrukcję SQL w jednym kroku, aby stwierdzić, że muszę tylko rozwiązać ten problem.
Wskazówka: Jeśli pracujesz z bardzo dużą bazą danych, wtedy może być sensowne wykonanie mniejszej kopii jako wersji deweloperskiej lub testowej i używanie jej do pisania zapytań. W ten sposób nie zmniejszasz wydajności produkcyjnej bazy danych i nie zniechęcasz wszystkich Ciebie.
W naszym pierwszym kroku wymienimy wszystkich pracowników. Aby to zrobić, dołączymy tabelę Employee do tabeli Person, abyśmy mogli uzyskać nazwisko pracownika.
Oto dotychczasowe zapytanie
SELECT E1.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Jeśli spojrzysz na wynik, zobaczysz, że mamy wszystkie elementy wniosku kierownika HR, z wyjątkiem tego wyświetlamy każdego pracownika
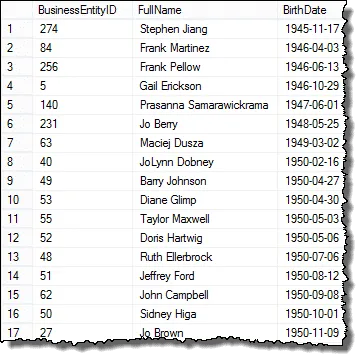
W następnym kroku ustawimy wyniki, abyśmy mogli rozpocząć porównywanie dat urodzenia, aby znaleźć zduplikowane wartości.
KROK 2 – Porównaj daty urodzenia, aby zidentyfikować duplikaty.
Teraz, gdy mamy listę pracowników, potrzebujemy teraz środków do porównywania dat urodzenia, abyśmy mogli zidentyfikować pracowników z tymi samymi datami urodzenia. Na ogół są to zduplikowane wartości.
Aby wykonać porównanie, wykonamy samosprzężenie w tabeli pracowników. Samołączenie to tylko uproszczona wersja WEWNĘTRZNEGO SPRZĘŻENIA. Zaczynamy od daty urodzenia jako warunku dołączenia. Gwarantuje to, że pobieramy tylko pracowników z tą samą datą urodzenia.
SELECT E1.BusinessEntityID, E2.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDateORDER BY E1.BirthDate, FullName
Dodałem do zapytania E2.BusinessEntityID, aby można było porównać klucz podstawowy z obu E1 i E2. W wielu przypadkach widzisz, że są one takie same.
Powodem, dla którego skupiamy się na BusinessEntityID, jest to, że jest to klucz podstawowy i unikalny identyfikator tabeli. Staje się to bardzo zwięzłym i wygodnym sposobem identyfikacji wyników wiersza i zrozumienia jego źródła.
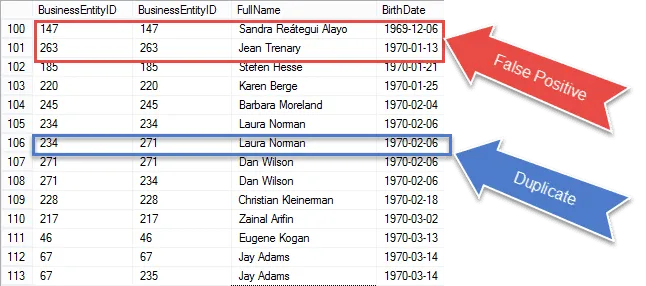
Jesteśmy coraz bliżej uzyskania ostatecznego wyniku, ale gdy już je sprawdzisz, zobaczysz, że: ponownie zbierasz ten sam rekord w meczu E1 i E2.
Sprawdź pozycje zakreślone na czerwono. To są fałszywe alarmy, które musimy wyeliminować z naszych wyników. To są te same wiersze, które pasują do siebie.
Dobra wiadomość jest taka, że jesteśmy naprawdę blisko zidentyfikowania samych duplikatów.
Zakreśliłem duplikat z gwarancją 100% na niebiesko. Zwróć uwagę, że BusinessEntityID są różne. Oznacza to, że samozłączenie jest zgodne z datą urodzenia w różnych wierszach – dla pewności są to prawdziwe duplikaty.
W następnym kroku weźmiemy te fałszywe alarmy i usuniemy je z naszych wyników.
Krok 3 – Eliminacja dopasowań do tego samego wiersza – Usuń fałszywie dodatnie
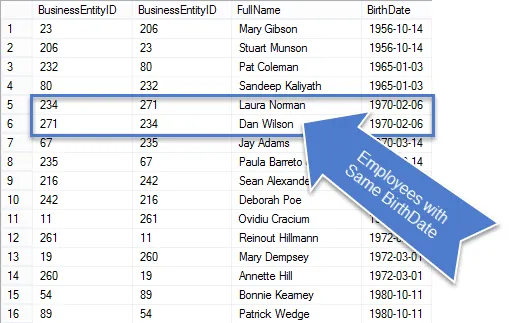
W poprzednim kroku mogłeś zauważyć, że wszystkie fałszywie dodatnie dopasowania mają ten sam BusinessEntityID; mając na uwadze, że prawdziwe duplikaty nie były równe.
To jest nasza wielka wskazówka.
Jeśli chcemy zobaczyć tylko duplikaty, musimy przywrócić tylko dopasowania z połączenia, w którym Wartości BusinessEntityID nie są równe.
Aby to zrobić, możemy dodać
E2.BusinessEntityID <> E1.BusinessEntityID
Jako warunek sprzężenia do naszego samozłączenia. Dodany warunek pokolorowałem na czerwono.
SELECT E1.BusinessEntityID, E2.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Po uruchomieniu tego zapytania zobaczysz mniej wierszy w wynikach, a te, które pozostaną są naprawdę duplikatami.
Ponieważ była to prośba biznesowa, wyczyśćmy zapytanie, abyśmy pokazali tylko żądane informacje.
Krok 4 – Ostatnie poprawki
pozbyć się wartości BusinessEntityID z zapytania. Były tam tylko po to, aby pomóc nam rozwiązać problem.
Tutaj znajduje się ostatnie zapytanie
SELECT P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
A oto wyniki, które możesz przedstawić Menedżer HR!
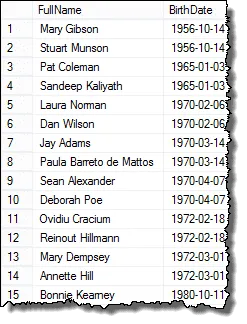
Mark, jeden z moich czytelników, zwrócił mi uwagę, że jeśli jest trzech pracowników, którzy mają takie same daty urodzenia, w ostatecznym wyniku otrzymalibyście duplikaty. Sprawdziłem to i to prawda. Aby lista pokazała każdy duplikat tylko raz, możesz użyć klauzuli DISTINCT. To zapytanie działa we wszystkich przypadkach:
SELECT DISTINCT P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Uwagi końcowe
Podsumowując, oto kroki, które podjęliśmy, aby zidentyfikować zduplikowane dane w naszej tabeli .
- Najpierw utworzyliśmy zapytanie dotyczące danych, które chcemy wyświetlić. W naszym przykładzie był to pracownik i jego data urodzenia.
- Wykonaliśmy samosprzężenie, INNER JOIN na tym samym stole w języku maniaków i używając pola, które uznaliśmy za zduplikowane. W naszym przypadku chcieliśmy znaleźć zduplikowane daty urodzin.
- Na koniec wyeliminowaliśmy dopasowania z tego samego wiersza, wykluczając wiersze, w których klucze główne były takie same.
Biorąc krok po kroku widać, że podczas tworzenia zapytania wykonaliśmy wiele zgadywania.
Jeśli chcesz ulepszyć sposób pisania zapytań lub po prostu jesteś przez to zdezorientowany i szukasz sposób na pozbycie się mgły, więc mogę zasugerować mój przewodnik Trzy kroki do lepszego SQL.