Como posso encontrar valores duplicados no SQL Server?
Neste artigo, descubra como encontrar valores duplicados em uma tabela ou exibição usando SQL. Percorreremos o processo passo a passo. Começaremos com um problema simples, construiremos lentamente o SQL até atingir o resultado final.
No final, você entenderá o padrão usado para identificar valores duplicados e será capaz de usar em seu banco de dados.
Todos os exemplos desta lição são baseados no Microsoft SQL Server Management Studio e no banco de dados AdventureWorks2012. Você pode começar a usar essas ferramentas gratuitas usando meu Guia de primeiros passos com o SQL Server.
Encontre valores duplicados no SQL Server
Vamos começar. Vamos basear este artigo em uma solicitação do mundo real; o gerente de recursos humanos gostaria que você localizasse todos os funcionários que compartilham o mesmo dia de aniversário. Ela gostaria que a lista fosse classificada por Data de nascimento e Nome do funcionário.
Depois de olhar o banco de dados, fica claro que a tabela HumanResources.Employee é a que deve ser usada, pois contém as datas de nascimento dos funcionários.
Em à primeira vista, parece que seria muito fácil encontrar valores duplicados no servidor SQL. Afinal, podemos classificar os dados facilmente.
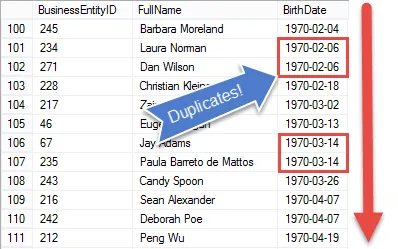
Mas uma vez que os dados são classificados, fica mais difícil! Como o SQL é uma linguagem baseada em conjuntos, não há uma maneira fácil, exceto pelo uso de cursores, de saber os valores do registro anterior.
Se soubéssemos disso, poderíamos apenas comparar os valores, e quando eles eram os mesmo sinaliza os registros como duplicados.
Felizmente, há outra maneira de fazermos isso. Usaremos um INNER JOIN para combinar os aniversários dos funcionários. Ao fazer isso, teremos uma lista de funcionários que compartilham a mesma data de nascimento.
Este será um artigo criado à medida que você avança. Vou começar com uma consulta simples, mostrar os resultados e apontar o que precisa de refinamento e seguir em frente. Começaremos obtendo uma lista de funcionários e suas datas de nascimento.
Etapa 1 – Obtenha uma lista de funcionários classificados por data de nascimento
Ao trabalhar com SQL, especialmente em territórios desconhecidos, Acho que é melhor construir uma instrução em pequenos passos, verificando os resultados conforme você avança, em vez de escrever o SQL “final” em uma única etapa, para descobrir que preciso solucioná-lo.
Dica: se você está trabalhando com um banco de dados muito grande, então pode fazer sentido fazer uma cópia menor como sua versão de desenvolvimento ou teste e usá-la para escrever suas consultas. Dessa forma, você não mata o desempenho do banco de dados de produção e deixa todos chateados você.
Então, em nossa primeira etapa, vamos listar todos os funcionários. Para fazer isso, juntaremos a tabela Employee à tabela Person para para que possamos obter o nome do funcionário.
Esta é a consulta até agora
SELECT E1.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Se você olhar o resultado, verá que temos todos os elementos da solicitação do gerente de RH, exceto que estamos exibindo todos os funcionários
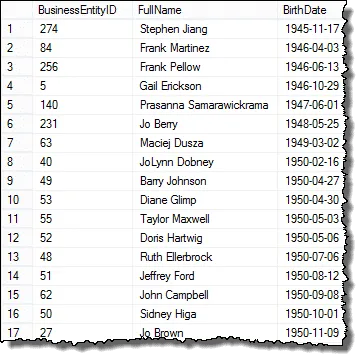
Na próxima etapa, configuraremos os resultados para que possamos começar a comparar datas de nascimento para encontrar valores duplicados.
ETAPA 2 – Comparar datas de nascimento para identificar duplicatas.
Agora que temos uma lista de funcionários, agora precisamos de um meio para comparar datas de nascimento para que possamos identificar funcionários com as mesmas datas de nascimento. Em geral, esses são valores duplicados.
Para fazer a comparação, faremos uma autojunção na tabela de funcionários. Uma autojunção é apenas uma versão simplificada de um INNER JOIN. Começamos usando BirthDate como nossa condição de junção. Isso garante que estejamos recuperando apenas funcionários com a mesma data de nascimento.
SELECT E1.BusinessEntityID, E2.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDateORDER BY E1.BirthDate, FullName
Eu adicionei E2.BusinessEntityID à consulta para que você possa comparar a chave primária de ambos E1 e E2. Em muitos casos, você vê que eles são iguais.
O motivo pelo qual estamos nos concentrando em BusinessEntityID é que ele é a chave primária e o identificador exclusivo da tabela. Torna-se um meio altamente conciso e conveniente de identificar os resultados de uma linha e entender sua origem.
Estamos chegando perto de obter nosso resultado final, mas quando você verificar os resultados, verá que ‘ re obtendo o mesmo recorde nas partidas E1 e E2.
Verifique os itens circulados em vermelho. Esses são os falsos positivos que precisamos eliminar de nossos resultados. Essas são as mesmas linhas que correspondem a elas mesmas.
A boa notícia é que estamos realmente perto de apenas identificar as duplicatas.
Eu circulei uma duplicata 100% garantida em azul. Observe que os BusinessEntityIDs são diferentes. Isso indica que a auto-junção está correspondendo à Data de nascimento em linhas diferentes – duplicatas verdadeiras, com certeza.
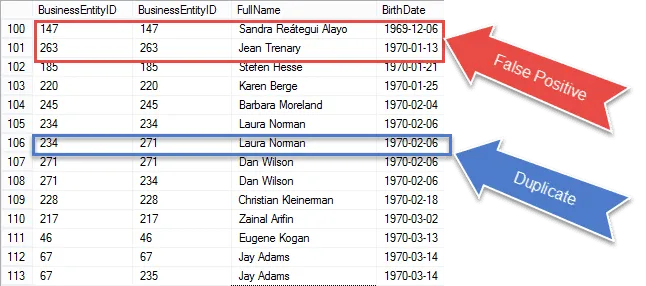
Na próxima etapa, examinaremos esses falsos positivos e os removeremos de nossos resultados.
Etapa 3 – Eliminar correspondências para a mesma linha – Remover falsos positivos
Na etapa anterior, você deve ter notado que todas as correspondências de falso positivo têm o mesmo BusinessEntityID; ao passo que as duplicatas verdadeiras não eram iguais.
Esta é nossa grande dica.
Se quisermos apenas ver as duplicatas, precisamos apenas trazer de volta as correspondências da junção onde o Os valores de BusinessEntityID não são iguais.
Para fazer isso, podemos adicionar
E2.BusinessEntityID <> E1.BusinessEntityID
Como uma condição de junção para nossa auto-junção. Eu pintei a condição adicionada em vermelho.
SELECT E1.BusinessEntityID, E2.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Depois que esta consulta for executada, você verá que há menos linhas nos resultados e as que permanecem são realmente duplicados.
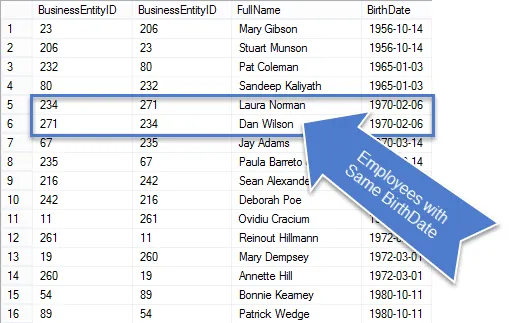
Como se trata de um pedido de negócios, vamos limpar a consulta para mostrar apenas as informações solicitadas.
Etapa 4 – toques finais
Vamos livrar-se dos valores BusinessEntityID da consulta. Eles estavam lá apenas para nos ajudar a solucionar o problema.
A consulta final está listada aqui
SELECT P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
E aqui estão os resultados que você pode apresentar para o gerente de RH!
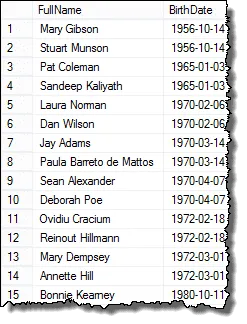
Mark, um dos meus leitores, me disse que se houver três funcionários com as mesmas datas de nascimento, você terá duplicatas nos resultados finais. Eu verifiquei isso e isso é verdade. Para retornar uma lista com cada duplicata apenas uma vez, você pode usar a cláusula DISTINCT. Esta consulta funciona em todos os casos:
SELECT DISTINCT P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Comentários finais
Para resumir, aqui estão as etapas que realizamos para identificar dados duplicados em nossa tabela .
- Primeiro criamos uma consulta dos dados que desejamos visualizar. Em nosso exemplo, este era o funcionário e sua data de nascimento.
- Realizamos uma autojunção, INNER JOIN na mesma mesa em linguagem geek e, usando o campo, consideramos duplicado. Em nosso caso, queríamos encontrar aniversários duplicados.
- Finalmente eliminamos as correspondências para a mesma linha, excluindo linhas em que as chaves primárias eram as mesmas.
Tomando um abordagem passo a passo, você pode ver que eliminamos muitas suposições ao criar a consulta.
Se você está procurando melhorar a forma como escreve suas consultas ou está apenas confuso com tudo isso e procurando por uma maneira de limpar a névoa, então posso sugerir meu guia Três etapas para melhorar o SQL.