Algoritmul K-Near Neighbor (KNN) pentru învățarea automată
- K-Near Neighbor este unul dintre cei mai simpli algoritmi de învățare automată despre tehnica de învățare supravegheată.
- Algoritmul K-NN își asumă similitudinea dintre noul caz / date și cazurile disponibile și pune noul caz în categoria cea mai asemănătoare cu categoriile disponibile.
- Algoritmul K-NN stochează toate datele disponibile și clasifică un nou punct de date pe baza similarității. Acest lucru înseamnă că atunci când apar date noi, atunci acestea pot fi clasificate cu ușurință într-o categorie de suită bine folosind algoritmul K-NN.
- Algoritmul K-NN poate fi utilizat atât pentru regresie, cât și pentru clasificare, dar mai ales este utilizat pentru problemele de clasificare.
- K-NN este un algoritm non-parametric, ceea ce înseamnă nu face nicio presupunere cu privire la datele subiacente.
- Este, de asemenea, numit algoritm de leneș pentru cursanți, deoarece nu învață imediat din setul de instruire, ci stochează setul de date și, în momentul clasificării, efectuează un acțiune asupra setului de date.
- Algoritmul KNN în faza de antrenament stochează doar setul de date și atunci când obține date noi, atunci clasifică aceste date într-o categorie care este mult similară cu noile date.
- Exemplu: Să presupunem că avem o imagine a unei creaturi care seamănă cu pisica și câinele, dar vrem să știm fie că este o pisică sau un câine. Deci, pentru această identificare, putem folosi algoritmul KNN, deoarece funcționează pe o măsură de similaritate. Modelul nostru KNN va găsi caracteristicile similare ale noului set de date cu imaginile pentru pisici și câini și, pe baza celor mai similare caracteristici, îl va pune fie în categoria pisică, fie în câine.

De ce avem nevoie de un algoritm K-NN?
Să presupunem că există două categorii, și anume, categoria A și categoria B și avem un nou punct de date x1, deci acest punct de date se află în care dintre aceste categorii. Pentru a rezolva acest tip de problemă, avem nevoie de un algoritm K-NN. Cu ajutorul K-NN, putem identifica cu ușurință categoria sau clasa unui anumit set de date. Luați în considerare diagrama de mai jos:

Cum funcționează K-NN?
Funcționarea K-NN poate fi explicată pe baza algoritmul de mai jos:
- Pasul 1: Selectați numărul K al vecinilor
- Pasul 2: Calculați distanța euclidiană a numărului K al vecinilor
- Pasul 3: Luați cei mai apropiați K vecini conform distanței euclidiene calculate.
- Pasul 4: Dintre acești vecini k, numărați numărul de puncte de date din fiecare categorie.
- Pasul 5: Atribuiți noile puncte de date acelei categorii pentru care numărul vecinului este maxim.
- Pasul 6: Modelul nostru este gata.
Să presupunem că avem un nou punct de date și că trebuie să-l plasăm în categoria necesară. Luați în considerare imaginea de mai jos:

- În primul rând, vom alege numărul de vecini, deci vom alege k = 5.
- Apoi, vom calcula distanța euclidiană între punctele de date. Distanța euclidiană este distanța dintre două puncte, pe care le-am studiat deja în geometrie. Poate fi calculat ca:

- Calculând distanța euclidiană am obținut cei mai apropiați vecini, ca trei vecini cei mai apropiați din categoria A și doi vecini apropiați din categoria B. Luați în considerare imaginea de mai jos:

- După cum putem vedea, cei mai apropiați 3 vecini sunt din categoria A, prin urmare, acest nou punct de date trebuie să aparțină categoriei A.
Cum se selectează valoarea lui K în algoritmul K-NN?
Mai jos sunt câteva puncte pentru amintiți-vă în timp ce selectați valoarea K în algoritmul K-NN:
- Nu există un mod special de a determina cea mai bună valoare pentru „K”, deci trebuie să încercăm câteva valori pentru a găsi cea mai bună din ele. Cea mai preferată valoare pentru K este 5.
- O valoare foarte scăzută pentru K, cum ar fi K = 1 sau K = 2, poate fi zgomotoasă și poate duce la efectele valorilor aberante din model.
- Valorile mari pentru K sunt bune, dar pot întâmpina unele dificultăți.
Avantajele algoritmului KNN:
- Este simplu de implementat.
- Este robust față de datele de antrenament zgomotoase
- Poate fi mai eficient dacă datele de antrenament sunt mari.
Dezavantaje ale algoritmului KNN:
- Trebuie întotdeauna să determine valoarea lui K care poate fi complexă la un moment dat.
- Costul de calcul este ridicat datorită calculării distanței dintre punctele de date pentru toate eșantioanele de antrenament. .
Implementarea Python a algoritmului KNN
Pentru a realiza implementarea Python a algoritmului K-NN, vom folosi aceeași problemă și set de date pe care le-am folosit în Regresie logistică. Dar aici vom îmbunătăți performanța modelului. Mai jos este descrierea problemei:
Problema pentru algoritmul K-NN: Există o companie producătoare de automobile care a fabricat o mașină SUV nouă.Compania dorește să ofere reclame utilizatorilor interesați să cumpere acel SUV. Deci, pentru această problemă, avem un set de date care conține informații multiple ale utilizatorilor prin rețeaua socială. Setul de date conține o mulțime de informații, dar Salariul estimat și Vârsta le vom lua în considerare pentru variabila independentă și variabila Achiziționată este pentru variabila dependentă. Mai jos este setul de date:
Pași pentru implementarea algoritmului K-NN:
- Etapa de pre-procesare a datelor
- Montarea algoritmului K-NN la setul de instruire
- Prezicerea rezultatului testului
- Precizia testului rezultatului (crearea matricei de confuzie)
- Vizualizarea rezultatului setului de testare.
Pasul de pre-procesare a datelor:
Pasul de prelucrare a datelor va rămâne exact același cu regresia logistică. Mai jos este codul pentru aceasta:
Prin executarea codului de mai sus, setul nostru de date este importat în programul nostru și este bine pre-procesat. După scalarea caracteristicilor, setul nostru de date de testare va arăta astfel:
Din rezultatul de mai sus im vârstă, putem vedea că datele noastre sunt scalate cu succes.
- Montarea clasificatorului K-NN la datele de antrenament:
Acum vom încadra clasificatorul K-NN la datele de antrenament. Pentru a face acest lucru, vom importa clasa KNeighborsClassifier din biblioteca Sklearn Neighbours. După importarea clasei, vom crea obiectul Classifier al clasei. Parametrul acestei clase va fi- n_vecini: Pentru a defini vecinii necesari ai algoritmului. De obicei, este nevoie de 5.
- metric = „minkowski”: Acesta este parametrul implicit și decide distanța dintre puncte.
- p = 2: Este echivalent cu standardul Metrică euclidiană.
Și apoi vom încadra clasificatorul în datele de antrenament. Mai jos este codul pentru acesta:
Ieșire: Prin executarea codului de mai sus, vom obține ieșirea ca:
- Prezicerea rezultatului testului: Pentru a prezice rezultatul setului de testare, vom crea un vector y_pred așa cum am făcut în Regresia logistică. Mai jos este codul pentru acesta:
Ieșire:
Ieșirea pentru codul de mai sus va fi:
- Crearea matricei de confuzie:
Acum vom crea matricea de confuzie pentru modelul nostru K-NN pentru a vedea acuratețea clasificatorului. Mai jos este codul pentru acesta:
În codul de mai sus, am importat funcția confusion_matrix și am apelat-o folosind variabila cm.
Ieșire: executând codul de mai sus, vom obține matricea după cum urmează:
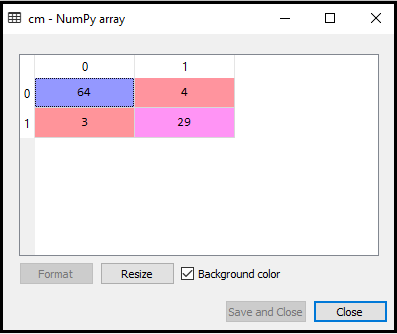
În imaginea de mai sus, putem vedea există 64 + 29 = 93 predicții corecte și 3 + 4 = 7 predicții incorecte, în timp ce, în regresia logistică, au existat 11 predicții incorecte. Deci, putem spune că performanța modelului este îmbunătățită prin utilizarea algoritmului K-NN.
- Vizualizarea rezultatului setului de antrenament:
Acum, vom vizualiza rezultatul setului de antrenament pentru K -Modelul NN. Codul va rămâne același ca și în Regresia logistică, cu excepția numelui graficului. Mai jos este codul pentru acesta:
Ieșire:
Prin executarea codului de mai sus, vom obține graficul de mai jos:
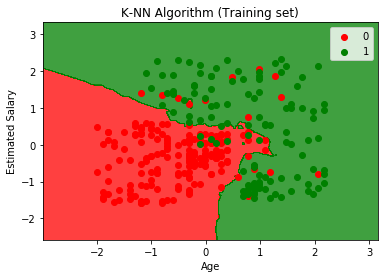
Graficul de ieșire este diferit de graficul pe care l-am avut în Regresie logistică. Poate fi înțeles în punctele de mai jos:
- După cum putem vedea, graficul arată punctul roșu și punctele verzi. Punctele verzi sunt pentru variabila Achiziționat (1) și Punctele roșii pentru variabila Necumpărat (0).
- Graficul arată o graniță neregulată în loc să arate orice linie dreaptă sau orice curbă deoarece este un algoritm K-NN, adică găsirea celui mai apropiat vecin.
- Graficul a clasificat utilizatorii în categoriile corecte, deoarece majoritatea utilizatorilor care nu au cumpărat SUV-ul se află în regiunea roșie, iar utilizatorii care au cumpărat SUV-ul se află în regiunea verde.
- Graficul arată rezultate bune, dar totuși, există câteva puncte verzi în regiunea roșie și puncte roșii în regiunea verde. Dar aceasta nu este o problemă importantă, deoarece prin realizarea acestui model se împiedică suprasolicitarea problemelor.
- Prin urmare, modelul nostru este bine antrenat.
- Vizualizarea rezultatului setului de testare:
După instruirea modelului, vom testa acum rezultatul punând un nou set de date, adică Set de date de testare. Codul rămâne același, cu excepția unor modificări minore: cum ar fi x_train și y_train vor fi înlocuite cu x_test și y_test.
Mai jos este codul pentru acesta:
Ieșire:
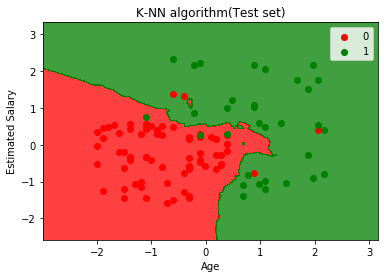
Graficul de mai sus arată ieșirea pentru setul de date de testare. După cum putem vedea în grafic, ieșirea prezisă este bună bine, deoarece majoritatea punctelor roșii se află în regiunea roșie și majoritatea punctelor verzi se află în regiunea verde.
Cu toate acestea, există puține puncte verzi în regiunea roșie și câteva puncte roșii în regiunea verde. Deci acestea sunt observațiile incorecte pe care le-am observat în matricea de confuzie (7 ieșire incorectă).