Cum pot găsi valori duplicate în SQL Server?
În acest articol aflați cum să găsiți valori duplicate într-un tabel sau vizualizare utilizând SQL. Vom parcurge pas cu pas procesul. Vom începe cu o problemă simplă, vom construi încet SQL, până când vom obține rezultatul final.
Până la final veți înțelege modelul folosit pentru a identifica valorile duplicate și veți putea folosi în baza dvs. de date.
Toate exemplele pentru această lecție se bazează pe Microsoft SQL Server Management Studio și baza de date AdventureWorks2012. Puteți începe să utilizați aceste instrumente gratuite folosind Ghidul meu Introducere în utilizarea SQL Server.
Găsiți valori duplicate în SQL Server
Să începem. Vom baza acest articol pe o cerere din lumea reală; managerul de resurse umane ar dori să găsiți toți angajații care au aceeași zi de naștere. I-ar plăcea lista sortată după BirthDate și EmployeeName.
După ce a analizat baza de date, devine evidentă tabela HumanResources.Employee este cea care trebuie utilizată, deoarece conține date de naștere ale angajaților.
La la prima vedere se pare că ar fi destul de ușor să găsești valori duplicat în serverul SQL. La urma urmei, putem sorta cu ușurință datele.
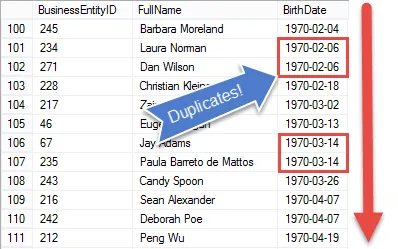
Dar odată ce datele sunt sortate, devine mai greu! Deoarece SQL este un limbaj bazat pe set, nu există o modalitate ușoară, cu excepția utilizării cursorelor, de a cunoaște valorile înregistrării anterioare.
Dacă le-am ști, am putea compara valorile și când acestea au fost semnalează înregistrările ca duplicate.
Din fericire, există o altă modalitate de a face acest lucru. Vom folosi un INNER JOIN pentru a se potrivi zilelor de naștere ale angajaților. Procedând astfel, vom obține o listă a angajaților care împărtășesc aceeași dată de naștere.
Acesta va fi un articol de construcție pe măsură ce mergeți. Voi începe cu o interogare simplă, voi arăta rezultatele și voi arăta ce necesită rafinament și voi continua. Vom începe cu obținerea unei liste de angajați și a datelor de naștere ale acestora.
Pasul 1 – Obțineți o listă a angajaților sortați după data de naștere
Când lucrați cu SQL, în special pe teritoriul neexplorat, Consider că este mai bine să construiesc o declarație în pași mici, verificând rezultatele pe măsură ce mergeți, mai degrabă decât să scrieți „finalul” SQL într-un singur pas, pentru a găsi doar că trebuie să o depanez.
Sugestie: Dacă lucrați cu o bază de date foarte mare, atunci ar putea avea sens să faceți o copie mai mică ca versiune de testare sau versiune de testare și să o utilizați pentru a scrie interogările dvs. În acest fel, nu ucideți performanța bazei de date de producție și faceți pe toată lumea dvs..
Deci, pentru primul nostru pas, vom enumera toți angajații. Pentru a face acest lucru, vom alătura tabela Angajaților la tabela Persoană pentru a putea obține numele angajatului.
Iată interogarea de până acum
SELECT E1.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Dacă vă uitați la rezultat, vedeți că avem toate elementele cererii managerului de resurse umane, cu excepția faptului că afișăm fiecare angajat
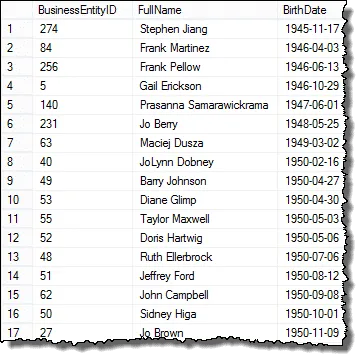
În pasul următor vom configura rezultatele, astfel încât să putem începe să comparăm datele de naștere pentru a găsi valori duplicat.
PASUL 2 – Comparați datele de naștere pentru a identifica duplicatele.
Acum că avem o listă de angajați, acum avem nevoie de un mijloc pentru a compara datele de naștere, astfel încât să putem identifica angajații cu aceleași date de naștere. În general, acestea sunt valori duplicat.
Pentru a face comparația, vom face o auto-alăturare pe masa angajaților. Un self-join este doar o versiune simplificată a unui INNER JOIN. Începem să folosim BirthDate ca condiție de înscriere. Acest lucru asigură că preluăm doar angajați cu aceeași dată de naștere.
SELECT E1.BusinessEntityID, E2.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDateORDER BY E1.BirthDate, FullName
Am adăugat E2.BusinessEntityID la interogare, astfel încât să puteți compara cheia primară din ambele E1 și E2. În multe cazuri, vedeți că sunt aceleași.
Motivul pentru care ne concentrăm asupra BusinessEntityID este că este cheia principală și identificatorul unic pentru tabel. Devine un mijloc extrem de concis și convenabil de a identifica rezultatele unui rând și de a înțelege sursa acestuia.
Ne apropiem de obținerea rezultatului nostru final, dar odată ce verificați rezultatele, veți vedea că ” reluați același record atât în meciul E1, cât și în cel al lui E2.
Verificați articolele încercuite cu roșu. Acestea sunt falsurile pozitive pe care trebuie să le eliminăm din rezultatele noastre. Acestea sunt aceleași rânduri care se potrivesc între ele.
Vestea bună este că suntem aproape de a identifica doar duplicatele.
Am încercuit un duplicat garantat 100% în albastru. Observați că ID-urile BusinessEntity sunt diferite. Acest lucru indică faptul că auto-îmbinarea se potrivește cu Data nașterii pe diferite rânduri – duplicate adevărate pentru a fi sigur.
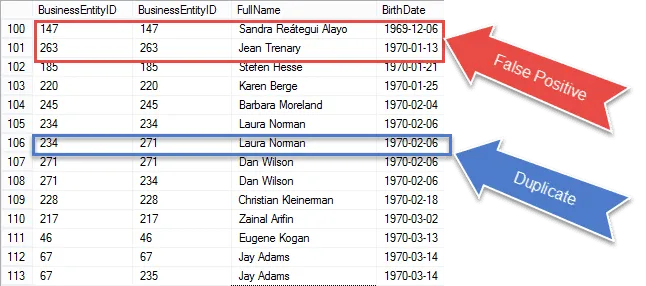
În pasul următor vom lua aceste pozitive false și le vom elimina din rezultatele noastre.
Pasul 3 – Eliminați potrivirile pe același rând – Eliminați pozitivele false
În pasul anterior este posibil să fi observat că toate potrivirile fals pozitive au același ID BusinessEntityID; întrucât, duplicatele adevărate nu au fost egale.
Acesta este marele nostru indiciu.
Dacă vrem să vedem doar duplicate, atunci trebuie să aducem înapoi doar meciuri de la unirea în care Valorile BusinessEntityID nu sunt egale.
Pentru a face acest lucru putem adăuga
E2.BusinessEntityID <> E1.BusinessEntityID
Ca condiție de asociere la auto-asociere. Am colorat condiția adăugată în roșu.
SELECT E1.BusinessEntityID, E2.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Odată ce această interogare este executată, veți vedea că există mai puține rânduri în rezultate și cele care rămân sunt cu adevărat duplicate.
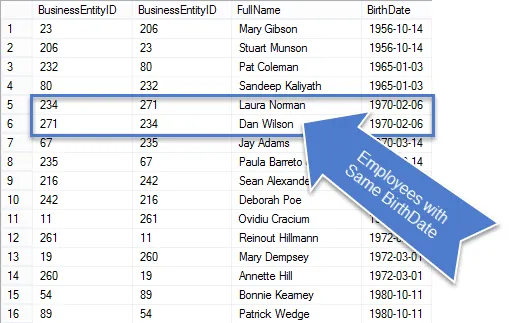
Întrucât aceasta a fost o cerere de afaceri, să curățăm interogarea, astfel încât să afișăm doar informațiile solicitate.
Pasul 4 – Atingeri finale
Să scăpați de valorile BusinessEntityID din interogare. Au fost acolo doar pentru a ne ajuta să depanăm.
Interogarea finală este listată aici
SELECT P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Și iată rezultatele pe care le puteți prezenta Managerul de resurse umane!
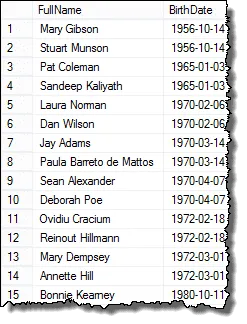
Mark, unul dintre cititorii mei, mi-a subliniat că dacă există trei angajați care au aceleași date de naștere, atunci veți avea duplicate în rezultatele finale. Am verificat acest lucru și este adevărat. Pentru a returna o listă afișează fiecare duplicat o singură dată, puteți utiliza clauza DISTINCT. Această interogare funcționează în toate cazurile:
SELECT DISTINCT P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Comentarii finale
Pentru a rezuma aici sunt pașii pe care i-am făcut pentru a identifica datele duplicate în tabelul nostru .
- Am creat mai întâi o interogare a datelor pe care dorim să le vizualizăm. În exemplul nostru, acesta a fost angajatul și data nașterii acestora.
- Am efectuat o auto-înscriere, INNER JOIN pe aceeași masă în vorbire geek și, folosind câmpul, am considerat că este duplicat. În cazul nostru am vrut să găsim zile de naștere duplicat.
- În cele din urmă am eliminat potrivirile pe același rând, excludând rândurile în care cheile principale erau aceleași.
Luând o abordare pas cu pas, puteți vedea că am făcut o mulțime de presupuneri din crearea interogării.
Dacă doriți să îmbunătățiți modul în care scrieți interogările dvs. sau sunteți doar confuzați de toate și căutați o modalitate de a curăța ceața, atunci îmi pot sugera ghidul meu Three Steps to Better SQL.