Hur kan jag hitta duplicerade värden i SQL Server?
I den här artikeln kan du ta reda på hur du hittar dubbla värden i en tabell eller vy med SQL. Vi går steg för steg genom processen. Vi börjar med ett enkelt problem, bygger långsamt upp SQL tills vi når slutresultatet.
I slutet kommer du att förstå mönstret som används för att identifiera dubbletter och kunna använda i din databas.
Alla exempel för den här lektionen är baserade på Microsoft SQL Server Management Studio och AdventureWorks2012-databasen. Du kan komma igång med dessa gratisverktyg med min guide Komma igång med SQL Server.
Hitta dubbletter av värden i SQL Server
Låt oss komma igång. Vi baserar den här artikeln på en verklig begäran; personalchefen vill att du hittar alla anställda som delar samma födelsedag. Hon vill ha listan sorterad efter BirthDate och EmployeeName.
Efter att ha tittat på databasen blir det uppenbart tabellen HumanResources.Anställda är den som ska användas eftersom den innehåller anställdas födelsedatum.
På vid första anblicken verkar det som om det skulle vara ganska enkelt att hitta dubbletter i SQL-servern. När allt kommer omkring kan vi enkelt sortera data.
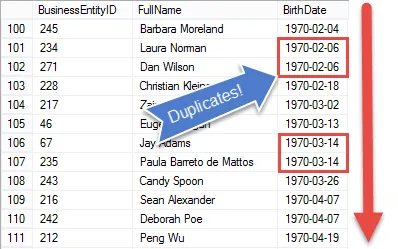
Men när data sorteras blir det svårare! Eftersom SQL är ett uppsättningsbaserat språk finns det inte ett enkelt sätt, förutom att använda markörer, att känna till den tidigare postens värden.
Om vi visste dessa kunde vi bara jämföra värden och när de var samma flagga posterna som dubbletter.
Lyckligtvis finns det ett annat sätt för oss att göra detta. Vi använder en INNER JOIN för att matcha anställdas födelsedagar. Genom att göra det får vi en lista över anställda som delar samma födelsedatum.
Det här kommer att bli en artikel som bygger på. Jag börjar med en enkel fråga, visar resultat och pekar på vad som behöver förfinas och går vidare. Vi börjar med att få en lista över anställda och deras födelsedatum.
Steg 1 – Få en lista över anställda sorterade efter födelsedatum
När du arbetar med SQL, särskilt i okartat territorium, Jag tycker att det är bättre att bygga ett uttalande i små steg, verifiera resultaten när du går, snarare än att skriva den ”slutliga” SQL i ett steg, för att bara hitta att jag behöver felsöka det.
Tips: Om du arbetar med en mycket stor databas, då kan det vara vettigt att göra en mindre kopia som din dev- eller testversion och använda den för att skriva dina frågor. På så sätt dödar du inte produktionsdatabasens prestanda och får alla ner på du.
Så för vårt första steg kommer vi att lista alla anställda. För att göra det kommer vi att gå med i tabellen Anställd till tabellen Person så att vi kan få anställdas namn.
Här är frågan hittills
SELECT E1.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Om du tittar på resultatet ser du att vi har alla delar av HR-chefens begäran, förutom att vi visar alla anställda
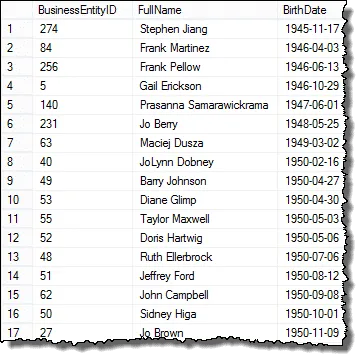
I nästa steg ställer vi in resultaten så att vi kan börja jämföra födelsedatum för att hitta dubbletter.
STEG 2 – Jämför födelsedatum för att identifiera dubbletter.
Nu när vi har en lista över anställda. Vi behöver nu ett sätt att jämföra födelsedatum så att vi kan identifiera anställda med samma födelsedatum. I allmänhet är detta dubbla värden.
För att göra jämförelsen gör vi en självanslutning på medarbetarbordet. En självanslutning är bara en förenklad version av en INNER JOIN. Vi börjar använda BirthDate som vårt anslutningsvillkor. Detta säkerställer att vi bara hämtar anställda med samma födelsedatum.
SELECT E1.BusinessEntityID, E2.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDateORDER BY E1.BirthDate, FullName
Jag lade till E2.BusinessEntityID i frågan så att du kan jämföra den primära nyckeln från båda E1 och E2. Du ser i många fall att de är desamma.
Anledningen till att vi fokuserar på BusinessEntityID är att det är den primära nyckeln och den unika identifieraren för tabellen. Det blir ett mycket kortfattat och bekvämt sätt att identifiera en rads resultat och att förstå källan.
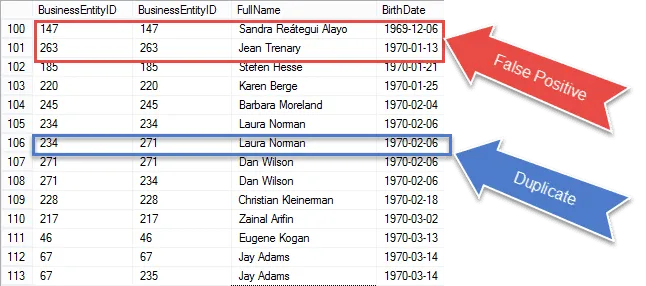
Vi närmar oss att få vårt slutliga resultat, men när du kolla in resultaten ser vi att vi ’ återhämtar samma post i både E1- och E2-matchningen.
Kolla in objekten som är inringade i rött. Det är de falska positiva resultaten som vi behöver eliminera från våra resultat. Det är samma rader som matchar sig själva.
Den goda nyheten är att vi verkligen är nära att bara identifiera dubbletterna.
Jag cirklar en 100% garanterad duplikat i blått. Lägg märke till att BusinessEntityID är annorlunda. Detta indikerar att självanslutningen matchar BirthDate på olika rader – riktiga dubbletter för att vara säker.
I nästa steg tar vi dessa falska positiva och tar bort dem från våra resultat.
Steg 3 – Eliminera matchningar till samma rad – Ta bort falska positiva resultat
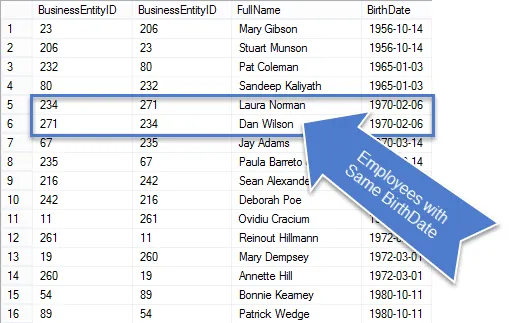
I föregående steg kanske du har märkt att alla falska positiva matchningar har samma BusinessEntityID; De verkliga dubbletterna var inte lika.
Detta är vår stora ledtråd.
Om vi bara vill se dubbletter, behöver vi bara ta tillbaka matchningar från föreningen där BusinessEntityID-värden är inte lika.
För att göra detta kan vi lägga till
E2.BusinessEntityID <> E1.BusinessEntityID
Som ett kopplingsvillkor för vår självanslutning. Jag har färgat det tillagda villkoret i rött.
SELECT E1.BusinessEntityID, E2.BusinessEntityID, P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
När denna fråga körs ser du att det finns färre rader i resultaten och de som finns kvar är verkligen dubbletter.
Eftersom detta var en affärsförfrågan, låt oss rensa frågan så att vi bara visar den begärda informationen.
Steg 4 – Sista handen
Låt oss bli av med BusinessEntityID-värdena från frågan. De var där bara för att hjälpa oss att felsöka.
Den slutliga frågan listas här
SELECT P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Och här är resultaten du kan presentera för HR-chefen!
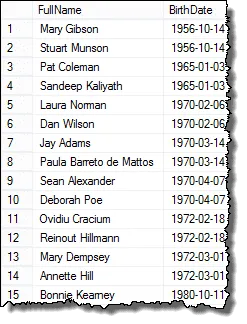
Mark, en av mina läsare, påpekade för mig att om det finns tre anställda som har samma födelsedatum så skulle du ha dubbletter i de slutliga resultaten. Jag verifierade detta och det är sant. För att returnera en lista som visar varje duplikat bara en gång kan du använda DISTINCT-satsen. Denna fråga fungerar i alla fall:
SELECT DISTINCT P.FirstName + " " + p.LastName AS FullName, E1.BirthDateFROM HumanResources.Employee AS E1 INNER JOIN Person.Person AS P ON P.BusinessEntityID = E1.BusinessEntityID INNER JOIN HumanResources.Employee AS E2 ON E2.BirthDate = E1.BirthDate AND E2.BusinessEntityID <> E1.BusinessEntityIDORDER BY E1.BirthDate, FullName
Slutliga kommentarer
För att sammanfatta här är de steg vi tog för att identifiera dubbletter i vår tabell .
- Vi skapade först en fråga om de data vi vill visa. I vårt exempel var detta den anställde och deras födelsedatum.
- Vi utförde en självanslutning, INNER JOIN på samma bord i geek speak, och med hjälp av fältet ansåg vi oss vara duplicerade. I vårt fall ville vi hitta dubbletter av födelsedagar.
- Slutligen eliminerade vi matchningar till samma rad genom att utesluta rader där primärnycklarna var desamma.
Genom att ta en steg för steg-tillvägagångssätt kan du se att vi tog en hel del gissningar i att skapa frågan.
Om du vill förbättra hur du skriver dina frågor eller bara blir förvirrad av allt och letar efter ett sätt att rensa dimman, då kan jag föreslå min guide Three Steps to Better SQL.